Anjana Data V2.0: mejoras en usabilidad y nuevas capacidades de customización del metamodelo CORE

Anjana Data lanza su versión 2.0 con funcionalidades mejoradas y con nuevas características de configuración, adaptación y customización para poder implantar un gobierno del dato ágil, flexible, proactivo y colaborativo.
El 2020 ha traído para Anjana Data una evolución en lo que respecta a sus funcionalidades y características tanto técnicas como de usabilidad, las cuales aportan un valor diferencial en el objetivo final de conseguir un Gobierno del Dato efectivo y eficiente, necesario para convertir el dato en un activo estratégico de cualquier organización.
Siguiendo la misma visión y filosofía del enfoque colaborativo centrado en los metadatos, se ha trabajado en cuatro vías principales:
- Facilitar el consumo de información por parte de los diferentes intervinientes y ampliar las capacidades de interacción entre los mismos con mejora de usabilidad
- Flexibilizar el metamodelo CORE para que este se adapte a las necesidades de la organización, ofreciendo nuevas capacidades de extensión y adaptación.
- Ampliar las capacidades de configuración y mantenimiento del modelo de gobierno
- Integración tecnológica con diferentes plataformas para ofrecer automatización end-2-end y aumento de capacidades de interoperabilidad a través de API.
A continuación detallamos las nuevas funcionalidades que ofrece la versión 2.0 de Anjana Data:
Mejoras de UX y UI
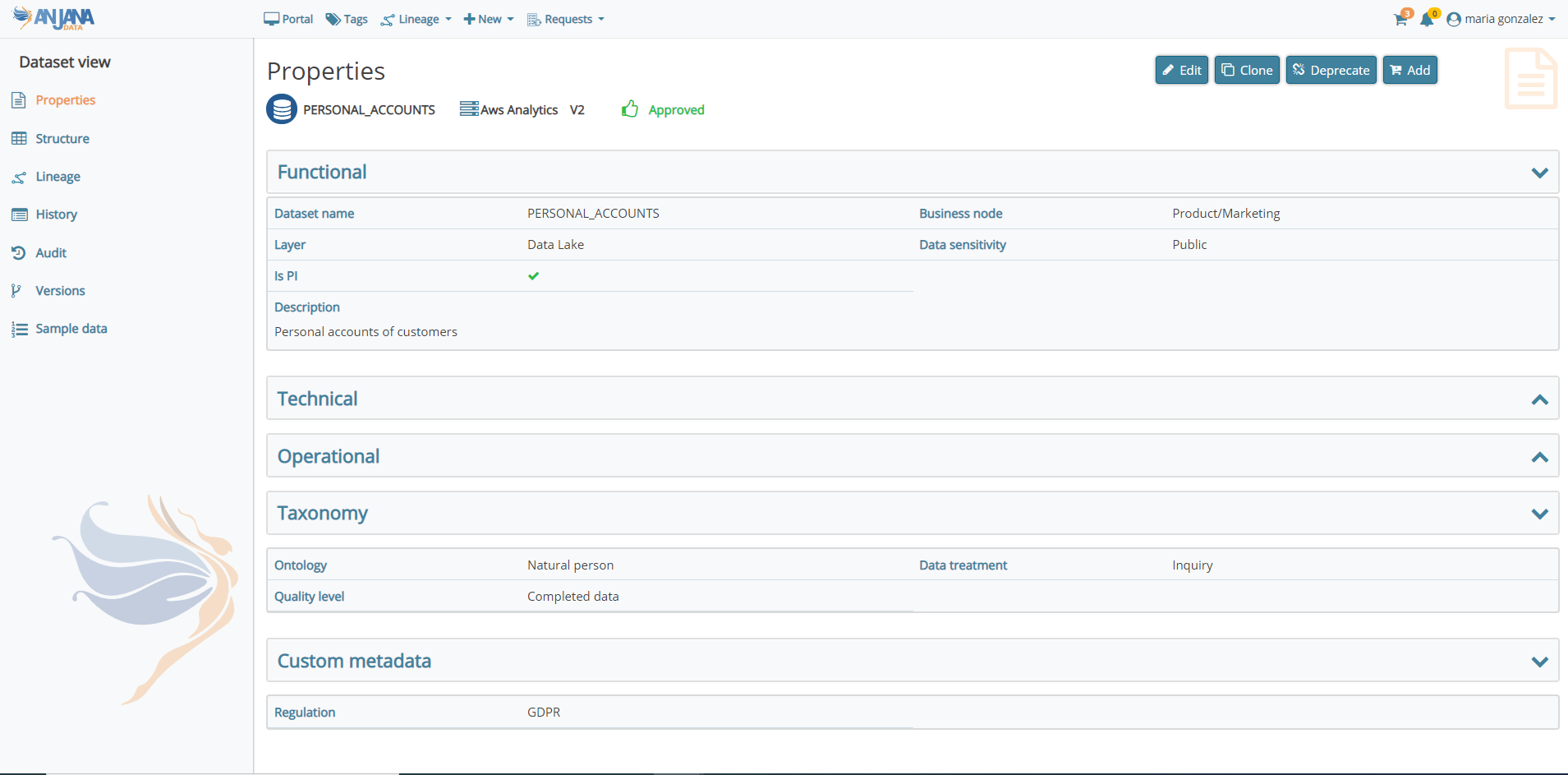
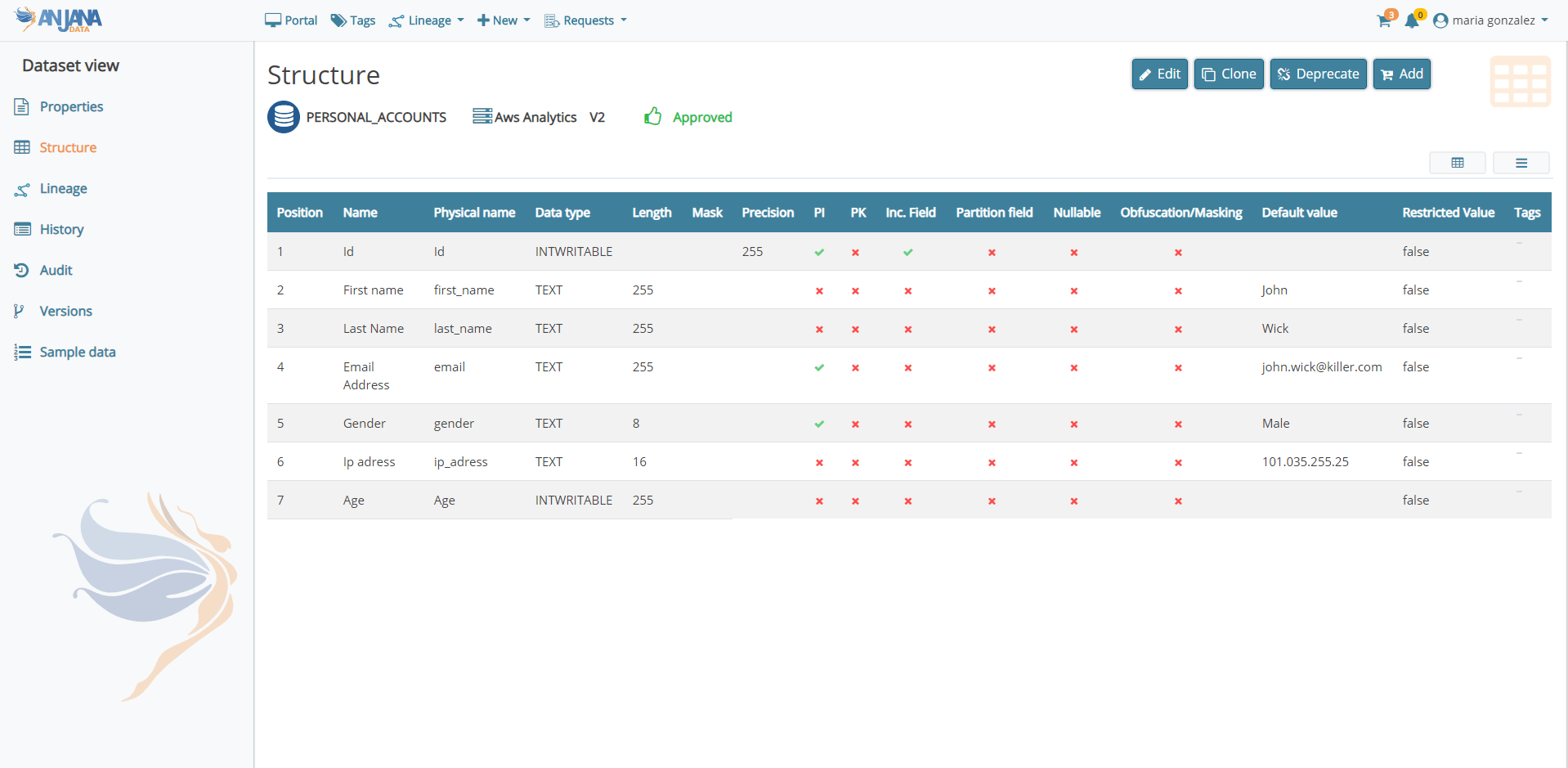
Con la premisa de entregar una versión de fácil usabilidad y que cumpla con la función de ser la solución central para el gobierno de los datos en una organización, Anjana Data presenta mejoras de experiencia e interfaz de usuario mediante cambios sustanciales en diferentes pantallas de la aplicación como el Portal de Datos, las vistas de detalle de los objetos, los grafos de linaje, la gestión de los workflows y el Panel de Administración.
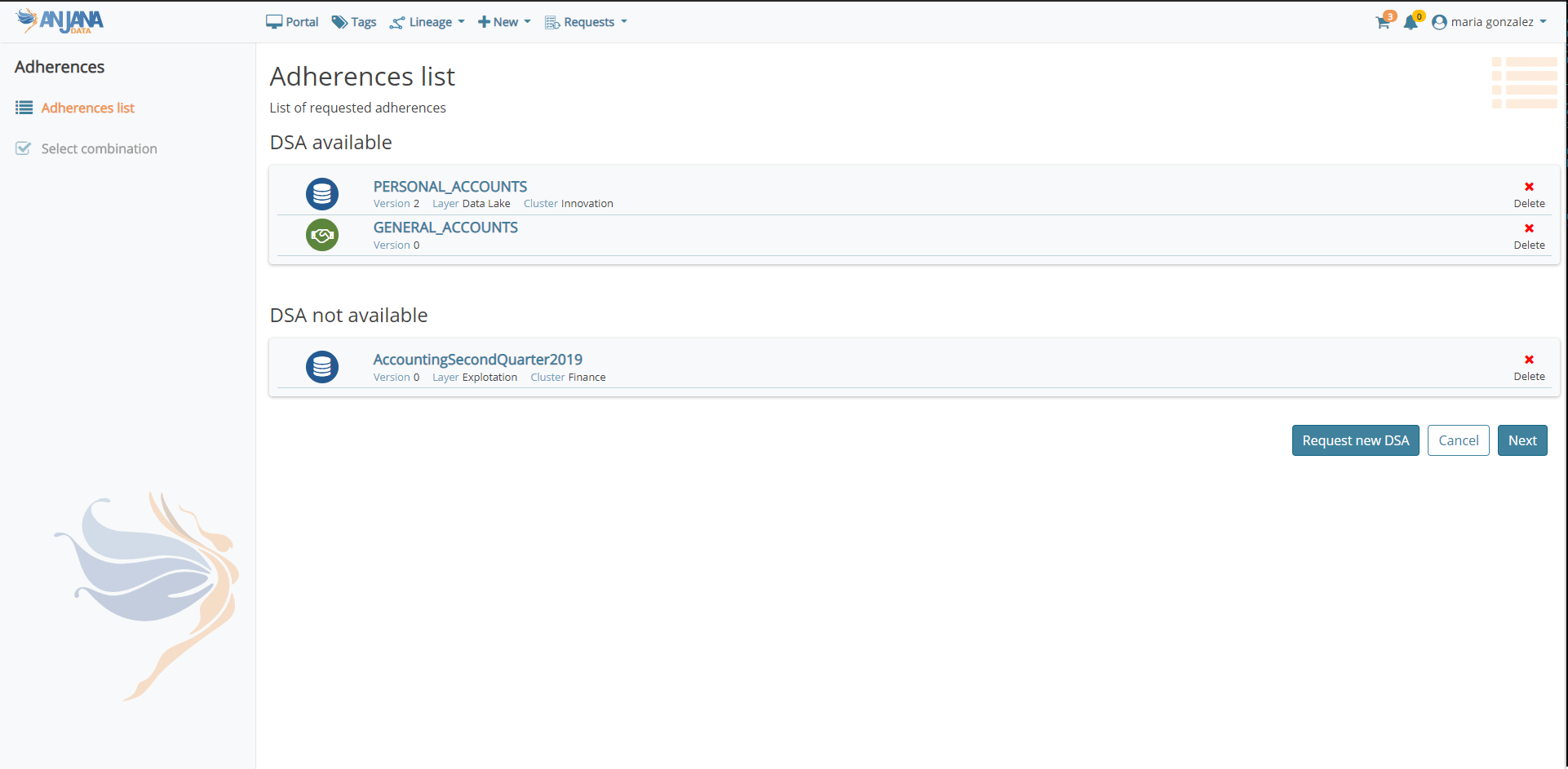
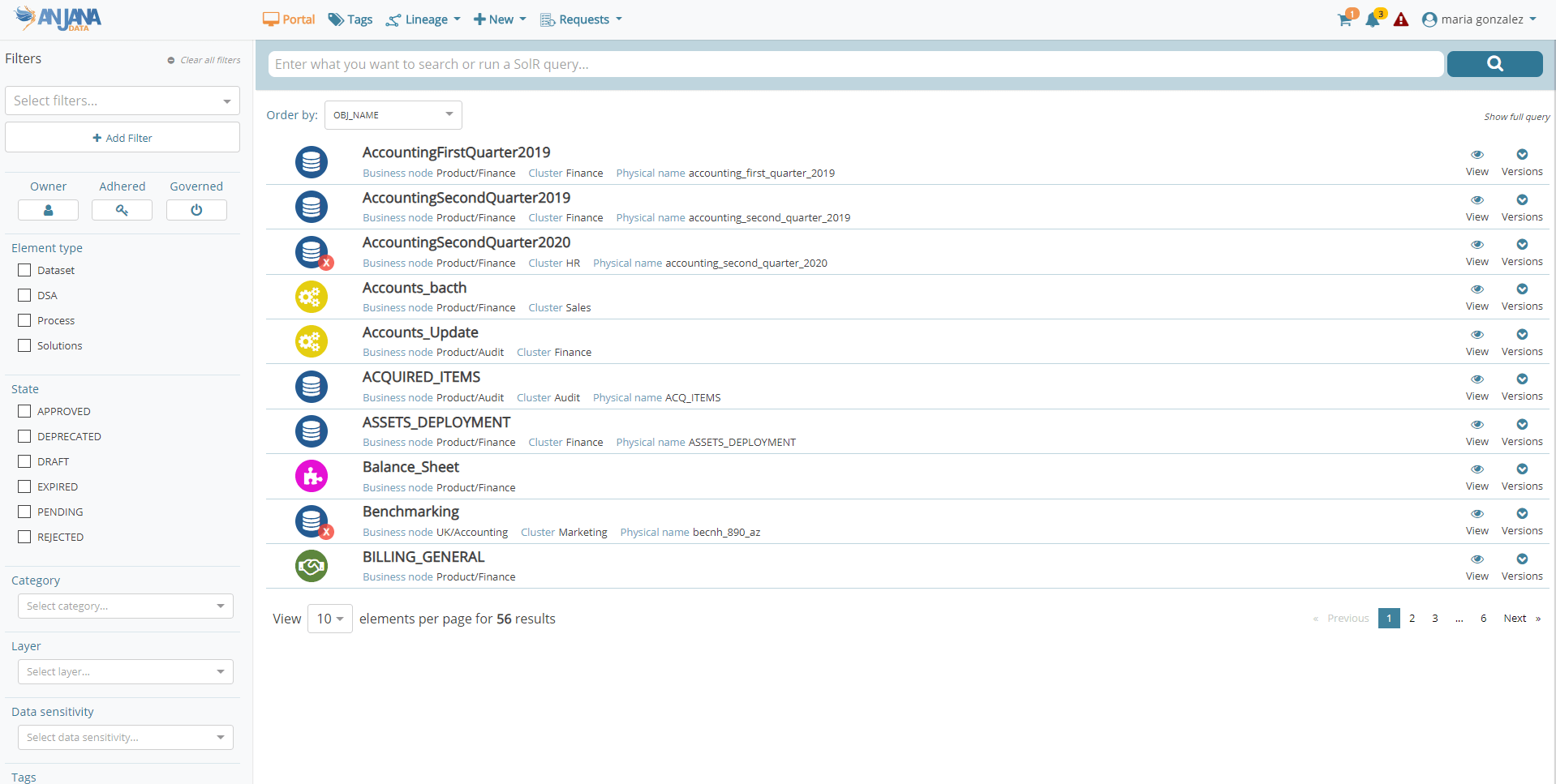
En el Portal de Datos se incluye un buscador más avanzado y optimizado, filtros dinámicos, nuevos iconos más intuitivos y una información más condensada para facilitar la búsqueda y descubrimiento de los activos de datos gobernados. Además, ahora la solución permite visualizar las propiedades de los objetos con diferentes vistas para adaptarse a la necesidad del consumo del usuario y también simplifica el proceso de carga masiva de objetos tanto desde Excel como por importación automática haciendo uso de los conectores disponibles o de la API.
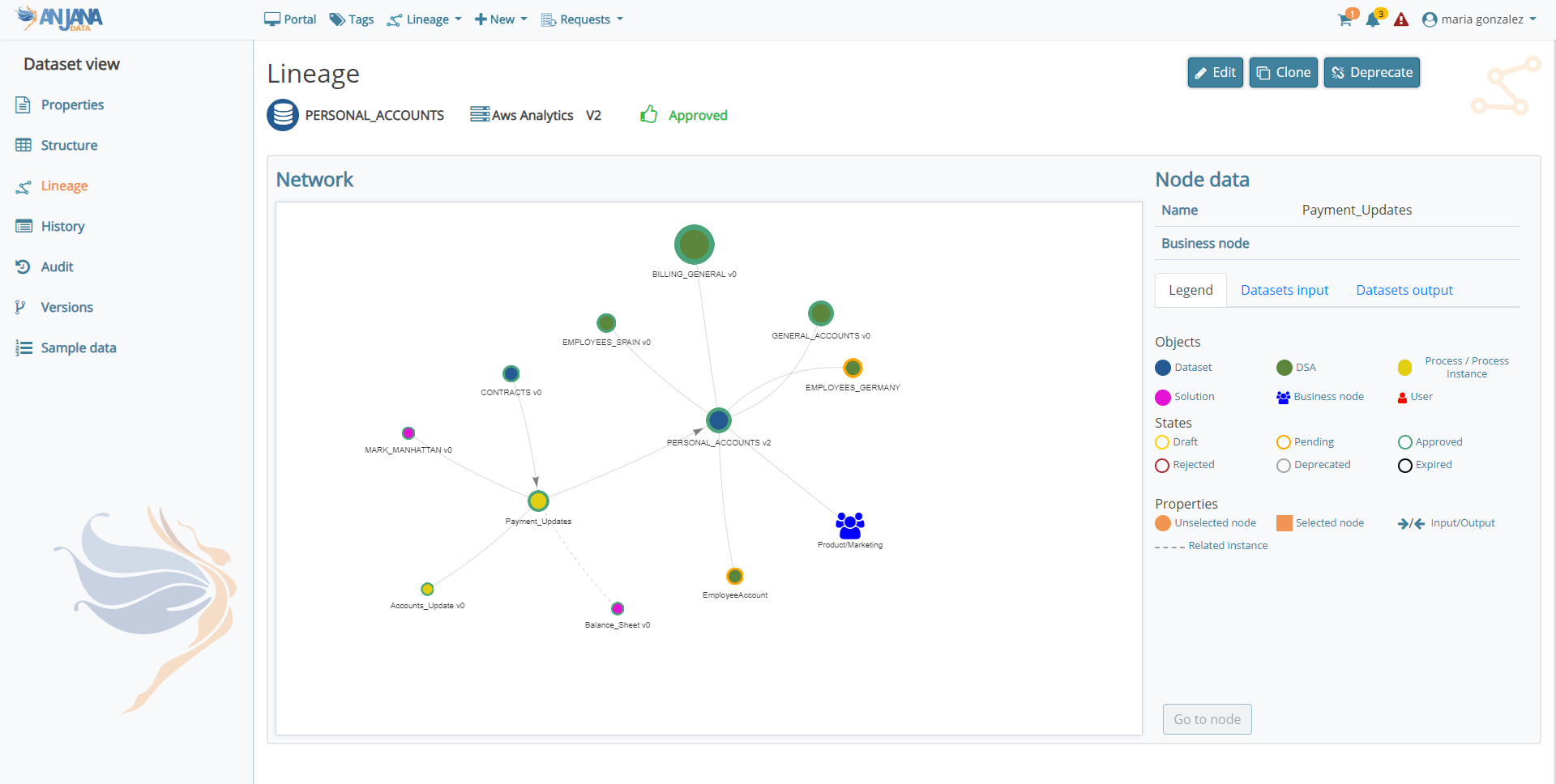
En relación a los grafos de linaje y trazabilidad, se incluyen nuevos elementos que facilitan la interpretación de los mismos, como la representación de los usuarios adheridos a DSAs, flechas direccionales que indican el sentido del flujo de los datos (datasets input >> proceso/instancia >> datasets output) y la diferenciación de instancias de procesos relacionadas respecto de las propias para las soluciones.
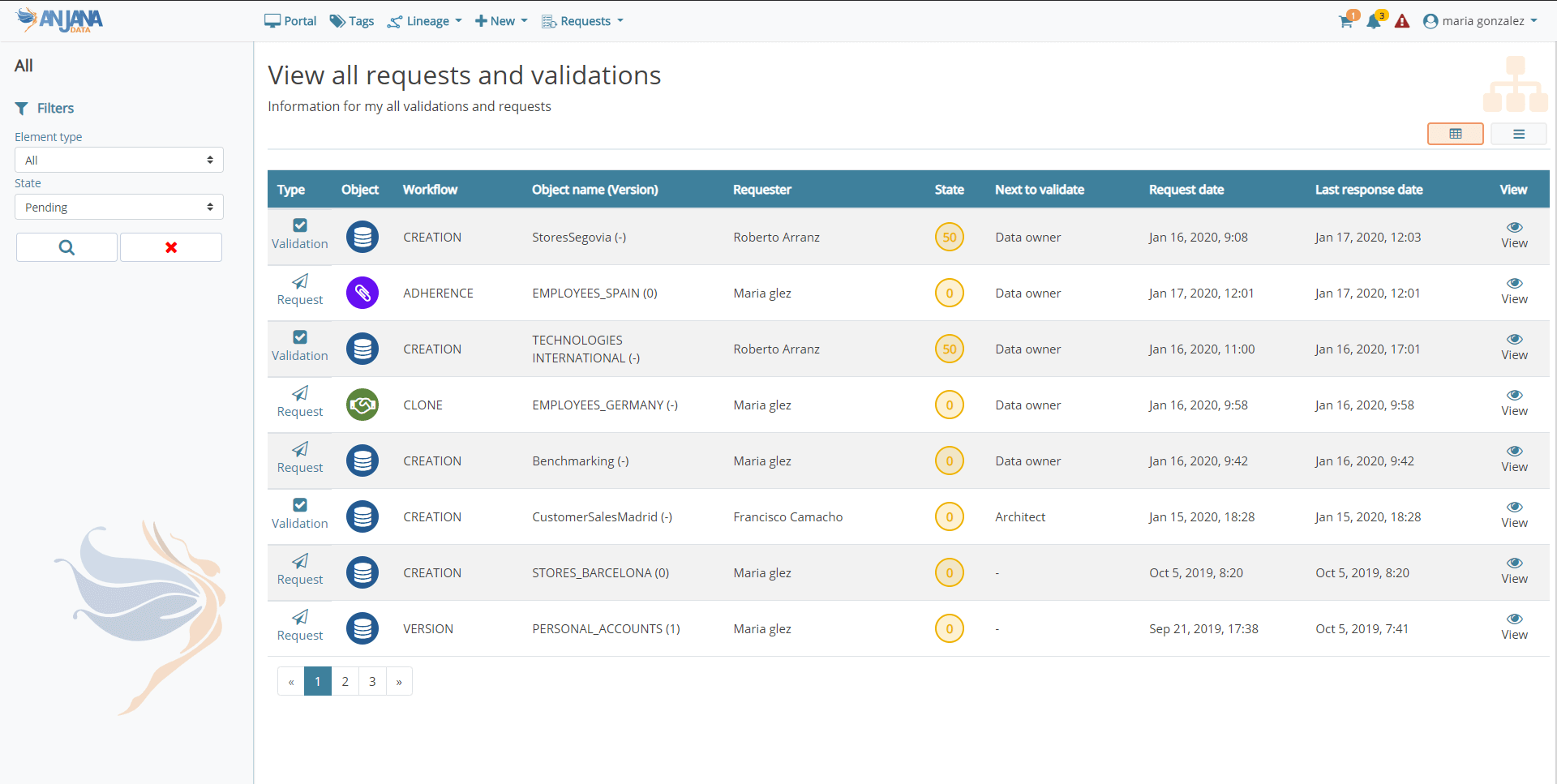
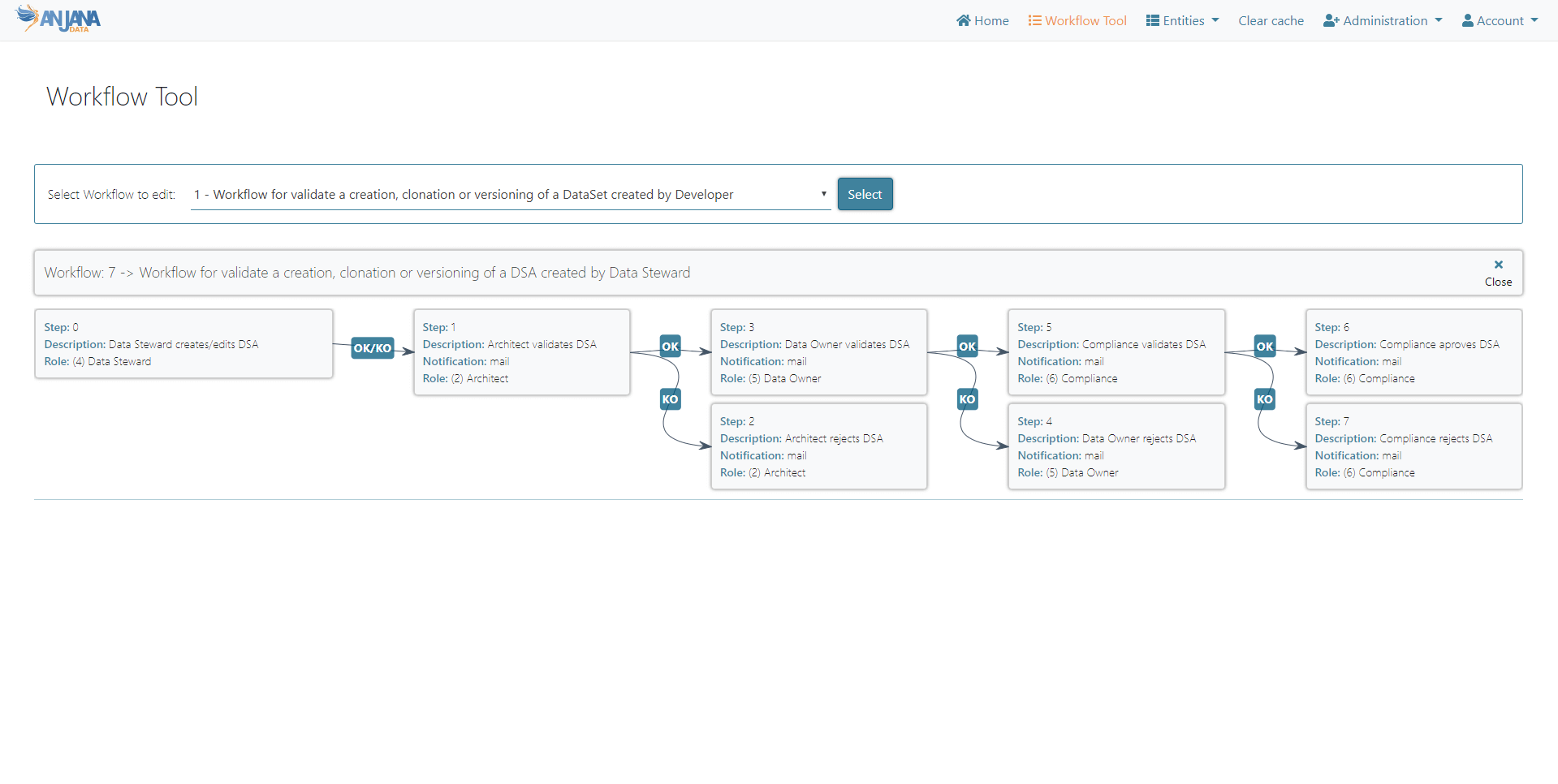
En cuanto a la visualización de workflows, también se disponen nuevas formas de consumir la información de cara a poder tener una visión global de las peticiones facilitando su seguimiento y ofreciendo la posibilidad de contar con todo el detalle disponible a golpe de click.
Finalmente, para facilitar la configuración y administración de la solución, se presenta un nuevo frontal desde el que se pueden realizar de forma gráfica todas las tareas de parametrización, gestión y mantenimiento del modelo de gobierno (áreas de negocio, roles, usuarios, permisos, workflows, taxonomías, gobierno pasivo vs activo, conexiones, catálogos de parámetros, tags, …).
Metamodelo CORE 2.0
En la nueva versión, el Metamodelo CORE de Anjana Data no sólo ha sido extendido con metadatos adicionales sino que además ofrece ahora la posibilidad de modificar las plantillas para los diferentes objetos. Esto permite centralizar la gestión de taxonomías y la inclusión de nuevos metadatos a lo largo del tiempo, según las necesidades de la organización.
Además, los usuarios podrán agregar metadatos específicos a objetos individuales según la configuración de sus permisos y podrán contar con catálogos predefinidos de tipos de datos para algunos campos basados en tecnologías y formatos compatibles.
Gobierno activo y linaje dinámico agnósticos a la tecnología y sobre nuevas plataformas de forma nativa
Ser la única plataforma de gobierno del dato que ofrece gobierno activo y linaje dinámico de forma agnóstica a las tecnologías de almacenamiento y tratamiento de datos no es sencillo y, por ello, esta nueva versión de Anjana Data trae consigo una nueva arquitectura simplificada, diseñada específicamente para facilitar la interacción con cualquier tecnología mediante el uso de servicios y ofreciendo capacidades de cómputo en memoria con escalabilidad horizontal ilimitada (sí, ilimitada, al más puro estilo Big Data).
Igualmente, para permitir una interoperabilidad total y garantizar una integración rápida y fácil en cualquier escenario tecnológico, Anjana Data dispone de una nueva capa optimizada de API pública totalmente documentada. Dicha capa ha sido ampliada con nuevas funciones para ofrecer todas las capacidades de Anjana Data al mundo exterior tanto de entrada como de salida.
Además, se ha continuado trabajando en la integración nativa con diferentes vendors y tecnologías como todo el stack de Cloudera (CDH y CDP), cualquier clúster Hadoop stand-alone que use tecnologías como Sentry, HDFS, Impala, Hive, Spark 2.x, … y soporte a todas las tecnologías que cumplan el estándar JDBC (BBDD relacionales en su mayoría tanto On-Premise como en Cloud).
De esta manera, se ha conseguido evolucionar una solución que ofrece a los diferentes roles involucrados, una mejor dinámica de trabajo y una óptima gestión de metadatos que facilita la extracción de valor al negocio y la toma de decisiones.
El futuro de Anjana Data
Esta nueva versión ofrece a nuestros clientes un importante salto de calidad pero, como no podría ser de otra forma, ya estamos desarrollando la próxima versión que será lanzada en abril de este año, ¿Qué podremos encontrar en esta próxima versión?
- Nuevas capacidades de integración nativa con diferentes plataformas y tecnologías, las cuales iremos anunciando conforme vayamos cerrando los acuerdos de partnership correspondientes que estamos gestionando.
- La nueva joya de la corona, un módulo de Business Glossary de última generación, totalmente flexible y configurable para adaptarse a la visión semántica de cualquier organización, pero 100% conectado con nuestro metamodelo central, ofreciendo la posibilidad de realizar un viaje completo del dato tanto top-down como bottom-up.
- Formularios dinámicos avanzados para la gestión de plantillas y composición de objetos.
- Rediseño de algunas interfaces e inclusión de mejoras de UX y UI con el objetivo de que la aplicación web de Anjana Data sea cada vez más sencilla e intuitiva y favorezca la interacción de los distintos tipos de roles y usuarios.
- Y, la guinda del pastel, capacidades de asistencialidad para algunas funcionalidades, gracias al análisis del comportamiento del usuario y la inclusión de algoritmos de análitica avanzada en segundo plano. Eso que a todo el mundo le gusta llamar “Inteligencia Artificial” y “Machine Learning”.