Anjana Data & LLM Hub
Desde Anjana Data llevamos algún tiempo involucrados en el gobierno de datos sobre diversas áreas, entre ellas ML y MLOPS. Un tiempo en el cual nuestro principal foco ha sido la inclusión de marcos o modelos de Gobierno del Dato que cubriesen estos escenarios, consiguiendo con ello, no solo incrementar la garantía de estos sistemas, sino también optimizando su explotación y correcta evolución.
Al juntar la experiencia en este ámbito y las investigaciones que realizamos sobre las actuales innovaciones, hemos obtenido un punto de vista arquitectónico al que hemos denominado “LLM Hub”; el cual nos parece de alto interés, ya que habilita el poder explotar las capacidades actuales y futuras de lo enmarcado en el concepto “IA Generativa” de una forma ágil, controlada, escalable y evolucionable en el tiempo.
Para exponerlo hemos organizado tres bloques en los que hablaremos sobre lo siguiente:
- Arquitectura LLM Hub e integración de sistemas en LLM Hub
- Propuesta de roadmap de integración de Anjana Data en LLM Hub
- Aplicación de gobierno del dato con Anjana Data sobre el mantenimiento evolutivo de LLM Hub y mecánicas MLOPS
En esta primera parte empezaremos por un simplificado resumen del estado actual del marco “IA Generativa”, pasando posteriormente a exponer de una forma simple y a alto nivel qué es lo que denominamos LLM Hub, qué aporta, las piezas lo componen, qué y cómo integra sistemas, y cómo puede evolucionar en el tiempo.
LLM Overview: State
Actualmente, los modelos LLM bajo el marco IA generativa están en auge y, aunque están en una fase temprana en la cual diariamente surgen variantes, optimizaciones y funcionalidades, sí se han estandarizado procesos clave para su generación, distribución y explotación.
Las capacidades actuales distan aun de poder realizar una amplia variedad de tareas en las que se espera un resultado determinista, pero por el contrario se dispone de una capacidad no antes disponible de una forma asumible para asistir y optimizar el consumo de información, gracias a su gran capacidad como agregadores información y las nuevas capacidades de generación de respuesta.
De forma adicional, la arquitectura que proponemos puede reciclar e incorporar sistemas construidos con anterioridad para que puedan aprovechar todas las ventajas actuales, no solo en función y capacidad, sino también en aplicar la actual estandarización que optimizará su mantenimiento evolutivo y explotación.
LLM Overview: Evolution
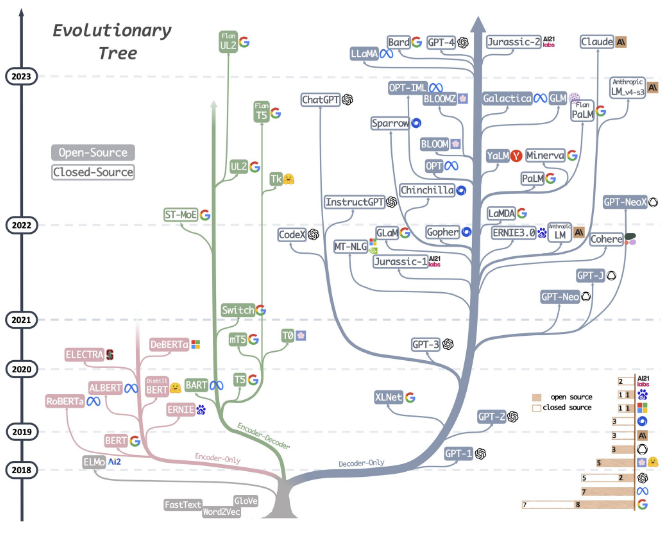
Recientemente se ha generado una disrupción con la publicación de Llama 2 por parte de Meta, punto desde el cual la comunidad y múltiples terceros han empezado a generar variantes y optimizaciones que junto a la base existente hacen altamente interesantes una gran cantidad de modelos.
Gracias a la estandarización de procesos, los modelos especializados empiezan a surgir constantemente como una forma natural de optimizar los requisitos y resultados de un modelo genérico o fundacional ante una determinada tipología de tarea.
De forma paralela, el interés en esta área ha movido a big players como los cloud a fomentar y construir servicios optimizados y casi pret a porter en muchos casos, con los que se facilita la adopción. Como más claros ejemplos esta la apuesta con OpenAI de Microsoft o la potenciación en IA hecha por AWS con Bedrock. También aparecen nuevos players que ofrecen directamente tenants privados de su tecnología como ChartGPT Enterprise o la inferencia como servicio, como el servicio de endpoints (api) ofrecidos por ChatGPT o huggingface
En corto plazo se espera una constante evolución basada en mejora, especialización y optimización, pero dado el alto volumen de participantes no es descartable en absoluto nuevos puntos de disrupción en cuanto a funcionalidad y capacidad.
El medio y largo plazo es algo imposible de dilucidar, pero si se puede observar que los procesos, formatos y mecanismos actuales son prácticamente un estándar de facto y son lo suficientemente flexibles para ser ajustados a las nuevas necesidades, por lo cual si cabe esperar que todo esto que hace explotable y mantenible a un modelo LLM evolucione, pero no tenga cambios disruptivos en corto o medio plazo.
LLM Overview: Current functionality
Como ya se ha expuesto, nuestro enfoque LLM Hub busca el aprovechar las actuales capacidades de agregación de información y generación de respuesta en tareas de asistencia al usuario.
El resultado deseado es que el usuario disponga de un punto de información en cual le exponga de una forma simple y concreta la información que necesita, la ventaja e innovación es que LLM Hub garantiza que la información entregada al usuario va a ser generada a partir de un conocimiento integro de toda la información y todos los contextos, evitando por tanto los constantes sesgos del propio usuario originados en que no es posible que el usuario de un área tenga pleno conocimiento del resto de áreas y la imposibilidad del mismo de poder consumir de una forma eficiente la información estática tipo manuales, bases de conocimiento etc.. Que normalmente está altamente fragmentada por su especialización y en muchas ocasiones directamente no es accesible.
¿Qué es lo que posibilita ese resultado deseado?
Lo posibilitan un conjunto de funciones actualmente disponibles y en este momento aplicables a gran escala, pero nos podemos centrar en las dos principales que nos interesan:
Capacidad de incorporación de contenidos, básicamente es la indexación de contenidos de cara a que el modelo pueda contextualizar las preguntas por un lado y adicionalmente usar dicha información para generar la respuesta (acercamiento llama-index, autogpt, gpt4all)
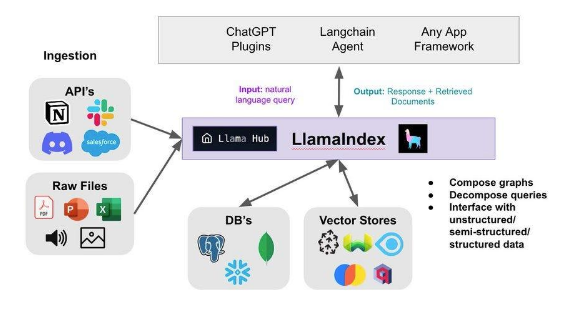
Capacidad de uso de agentes y herramientas, es un acercamiento generalizando el punto anterior, pero en el que se habilita un formato más sofisticado de “colaboración” ya que agentes y herramientas pueden interactuar con los contenidos indexados, entre ellos y con terceros sistemas, esto último incluso online, para generar respuestas. (acercamiento Langchain)
LLM HUB: what and how?
¿Qué es LLM Hub?
Simplificando a lo mínimo imprescindible y tomando alguna licencia, lo podemos definir como un sistema que contiene múltiples modelos, información indexada y agentes más herramientas, en un entorno en el cual se hace uso de las funciones de cada uno para que colaboren en la generación de una respuesta o actividad bajo unas determinadas reglas.
¿Cómo lo hace?
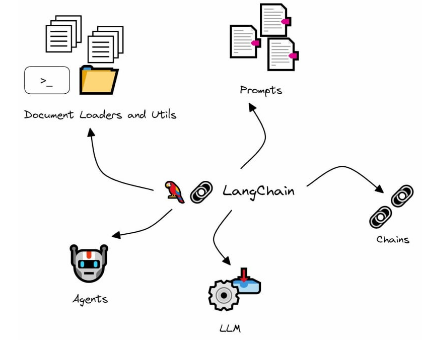
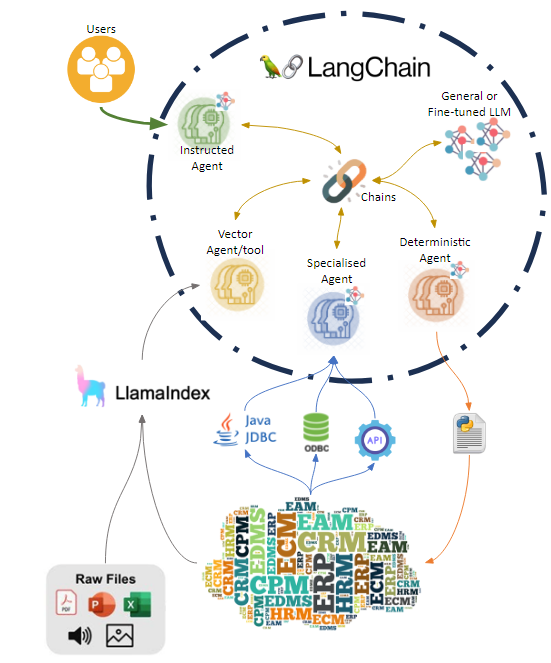
El sistema se apoya para orquestar la actividad con la funcionalidad que aporta LangChain e incluye reglas de segmentación de acceso a información y herramientas, aplicables en varios puntos para conseguir el conjunto de funcionalidad clave :
- Incorporar información directa online y offline mediante herramientas e indexación, el framework Llamaindex ha estandarizado la ingesta y actualización, llamaHub provee de los conectores habituales y de la posibilidad de implementar nuevos o especializaciones de los mismos.
- Incorporación del uso de modelos, agentes y herramientas especializados, ya que es asequible el fine-tunning de modelos es un error no explotarlo para adaptar comportamientos de modelos generales o fundacionales a tareas o áreas de conocimiento específicas
- Segmentación de acceso a información en base a perfilado de usuario, los agentes con los que interactúa el usuario disponen de reglas que restringen el uso de determinados agentes, herramientas y fuentes de información a los que el usuario no ha de tener acceso
- Agentes de uso específico, se pueden generar agentes especializados en determinadas tareas o determinados ámbitos e incluso que estos mismos agentes dispongan de su propio modelo LLM y herramientas, no obstante, tanto los modelos como las herramientas pueden ser compartidas entre agentes.
LLM HUB: where?
Uno de los grandes problemas actuales es asumir el costo de cómputo necesario para una aplicación a escala dentro de las compañías, aunque los modelos y técnicas se van optimizando día a día, el número de los posibles modelos a ejecutar y la envergadura de los mismos puede suponer un alto coste y no están diseñados para poder hacer liberaciones de recursos ni escalados en caliente o arranques en tiempos razonables.
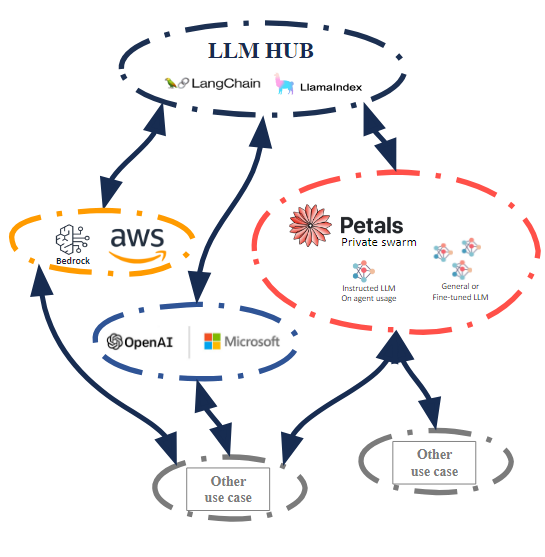
En este punto el uso de la arquitectura LLM Hub gracias a LangChain nos permite desligar los requerimientos e infraestructura necesarios para la ejecución de los modelos del resto de componentes. Con ello no solo obtenemos esta capacidad que posteriormente nos permitirá hacer escalados, al independizar los modelos y su cómputo sobre un punto independiente y agnóstico adicionalmente podemos compartir esa capacidad de cómputo para múltiples casos de uso y terceros que no sean LLM Hub
Se puede materializar en dos formatos que pueden ser incluso coexistentes:
- Granjas privadas, especialmente indicadas para preservar la localización de contenidos privados más sensibles, existen alternativas clásicas y basadas en contenedores, pero en este aspecto si nos atrevemos a proponer que se evalúe Petals dado que aporta una serie de funcionalidad adicional y una automatización de “caja” altamente interesante.
- Servicios de terceros, hay más variedad en la oferta, pero si es cierto que algunas de ellas crean dependencia del proveedor en determinados puntos, por suerte también hay servicios de endpoint de inferencia que si mantendrá agnóstico al LLM Hub en todo momento. En todo caso esta arquitectura LLM Hub puede ser perfectamente implementada sobre servicios tipo AWS Bedrock, que si genera dependencia, pero no pérdida de funcionalidad.
LLM HUB: Why Petals?
Como hemos hablado nos parece de alto interés la evaluación de este software (o funcionalmente similares) y podemos repasar de forma muy rápida y sin entrar en detalle técnico que es lo que aporta a parte de la obvia ganancia en privacidad y seguridad por la no obligatoria intervención de infraestructura o gestión de un tercero.
La inclusión de granjas privadas basada en la tecnología Petals desbloquea la capacidad de escalado y dimensionamiento de una forma ágil y controlada, dotando a LLM Hub de escalado de capacidad de cómputo y adicionalmente ofrece la capacidad de la fragmentación del cómputo requerido entre varios nodos, con lo que podemos ganar tanto en balanceo de carga como en alta disponibilidad. Veamos los tres puntos clave que habilitan esta capacidad tan interesante:
Fragmentación de capacidad requerida
Petals segrega los modelos por capas y estas son distribuidas entre los nodos disponibles, por tanto, nos dota de la capacidad de poder distribuir modelos entre nodos sumando la capacidad de los mismos para llegar al requerimiento de capacidad necesario
Escalado horizontal
Junto con la capacidad de fragmentación Petals se ve obligado a generar una red lógica de enrutamiento de peticiones la cual balancea entre los nodos que disponen de la misma capa del modelo de forma natural, por tanto, se pueden escalar nodos asignándole al mismo modelo para que repliquen capas o incluso las redistribuyen (se recomienda lo primero al no implicar indisponibilidad y ganar redundancia)
Escalado vertical
Dada la capacidad de escalado horizontal en caliente también se pueden aplicar escalados verticales sustituyendo nodos en caliente por nodos con más capacidad unitaria, se puede aplicar mediante una práctica de Rolling-update para evitar indisponibilidades.
LLM HUB: how to integrate systems?
Dada que la incorporación de modelos, fuentes, agentes y herramientas en LLM Hub es flexible e incremental cualquier tercero puede establecer un roadmap de integración aportando cualquiera de estos componentes en cualquier momento y pudiendo incorporar parte o la totalidad ya que cada uno dota de funcionalidad independiente.
Es recomendable en todo caso que sistemas de operación intenten entregar al menos conector y agente o herramienta en pack ya que estos dos componentes son altamente sinérgicos y habilitan a LLM Hub a generar una información con un alto diferencial con respecto a otros sistemas de información disponibles previamente.

Llama Hub connector
Generación de un nuevo conector que extraiga la información contenida en el producto para que sea indexada con facilidad y así poder contextualizar consultas o usar la información de forma general por cualquier modelo, agente u herramienta. En plataformas de base de conocimiento documentales se puede hacer uso de los conectores disponibles para directamente integrar esa documentación.
Specialised Agent / tool
Generación de un agente y/o herramienta que al ser inscrito o usada agregue a LLM Hub de la capacidad de consumir información del sistema, gracias a la contextualización previa los agentes pueden hacer uso de endpoints de consulta (búsqueda y similares) o incluso consumir datos en bases de datos para completar la generación de la respuesta con información online.
Deterministic Agent
Generación de un agente Langchain que al ser inscrito permita al HUB realizar acciones en el sistema tercero en nombre del usuario, el espectro a cubrir es muy variado, se recomienda agrupar las acciones en herramientas e incluso que ante mucha envergadura de acciones se pueda generar más de un agente para que cada uno trabaje segmentando acciones y herramientas de la forma más adecuada.