Governing is not cataloguing: understanding the market before starting a Data Governance & AI initiative
To govern is not to catalogue
Understanding the market before starting a Data Governance & AI initiative
In recent years, the data management market has changed significantly. It is no coincidence that Gartner no longer publishes the historical Magic Quadrant for Metadata Management Solutions to evolve into new categories such as Active Metadata Management and, more recently, the Magic Quadrant for Data & Analytics Governance Platforms.
This movement is not simply terminological. It reflects a market reality: not all solutions that manage metadata or catalogue assets are designed to govern data and AI from an organisational point of view..
Today, at least two major technological blocks coexist:
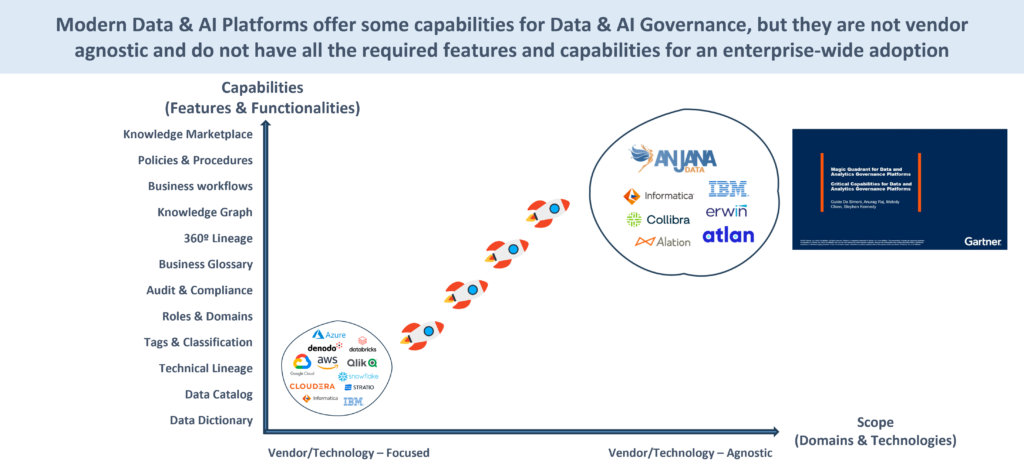
On the one hand, Data & AI Platforms that include technical governance capabilities within their own stack (Microsoft Fabric and Purview, AWS Glue Catalog, Lake Formation, DataZone and Sagemaker, Google Dataplex, Unity Catalog in Databricks, Snowflake Horizon, IBM, SAP, Oracle, Cloudera, Denodo, Qlik-Talend, Stratio, among others).
On the other hand, the independent and transversal Data Governance & AI Platforms, recognised as their own category by Gartner, where solutions such as Collibra, Informatica, Atlan, Alation, Erwin, DataGalaxy, etc. are located. Anjana Data Platform.
For a start-up organisation, understanding this differentiation is critical. Because the most common mistake is not choosing the wrong tool. It is not understanding what problem each type of solution is really solving.
Cataloguing vs Governing: a structural difference
Many organisations start their journey by activating the technical catalogue that is already included in your cloud or analytics platform. It makes sense: the functionality is available, the integration is easy and the value is immediate.
Tools such as Microsoft Purview, AWS Glue Catalog, Google Dataplex, Unity Catalog, Snowflake Horizon or Cloudera Catalog allow to automatically discover technical assets, extract structural metadata, infer technical lineage and classify sensitive information (with some limitations, of course). For architecture and data engineering teams, this is extremely useful.
But cataloguing is not governing.
To catalogue means to describe what exists. To govern means to decide how it should exist, who is responsible, under what rules it is built and how it is consumed.
A catalogue answers the question:
What technical assets do I have and how are they connected?
An organisational governance platform answers more complex questions:
Who is the Data Owner?
What policies do they apply?
Which contract regulates your consumption?
What is the impact of change?
How is this integrated into demand management and business processes?
From our experience in real projects - including organisations that have had to redesign their approach after several months of implementation - the confusion between the two concepts often leads to initiatives with a lot of technical visibility and little organisational control.
Technical vs. functional government
The native catalogues of cloud and data platforms serve a clear function: to provide technical governance within their own ecosystem.
- Purview and OneLake «rule» Azure and Fabric.
- Unity Catalog «governs» Databricks.
- Horizon «rules» Snowflake.
- Cloudera SDX «rules» Cloudera.
- Dataplex «governs» GCP.
- Glue Catalog, Lake Formation, DataZone and Sagemaker «rule» AWS.
Their integration is deep, their automation is powerful and their alignment with the underlying architecture is natural. They are very valuable pieces.
But their scope is limited to the technological field they control.
Functional governance, on the other hand, is about how the organisation structures domains, responsibilities, policies, data contracts, approval workflows and operational models. It is about how the entire lifecycle of data and AI assets is managed from an organisational perspective, not just a technical one.
This is where the Data Governance & AI Platforms recognised by Gartner as a differentiated category appear. These platforms - Collibra, Informatica, Atlan, Alation, among others - are born with a transversal vocation, not as an extension of a single technological architecture.
Anjana does not compete with the native technical governance of Data & AI Platforms. It elevates it to a higher layer of comprehensive, cross-cutting, agnostic and business-oriented governance..
It does not replace technical governance. It complements it and integrates it into a broader organisational framework..
Passive and reactive government vs. proactive and preventive government
There is another, less visible but equally critical distinction.
A purely technical catalogue-based model tends to be reactive.. Discover assets once they are built. Detects changes when they have already occurred. Classifies information after it has been created.
It is a government after the fact.
A proactive governance model integrates governance by design. Declares assets prior to construction. Define rules and responsibilities before going into production. Assess impacts before implementing changes.
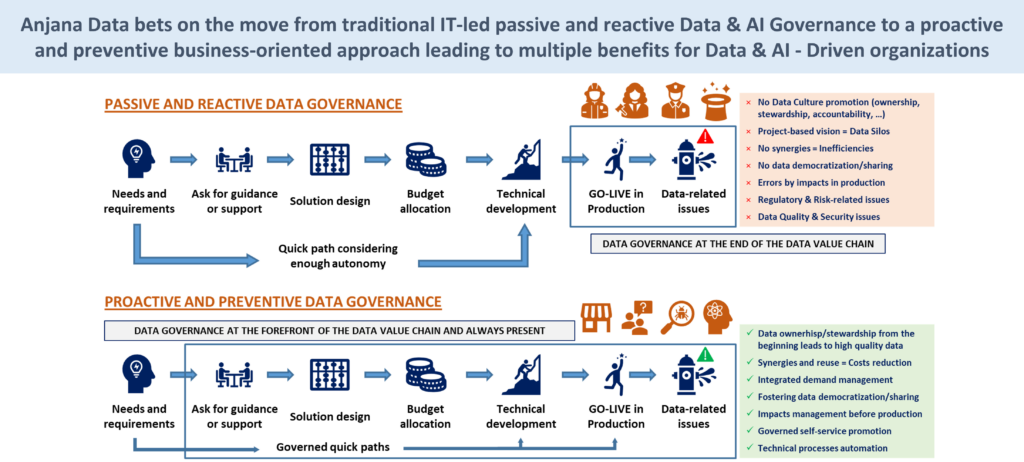
In organisations that aspire to models such as Data Mesh y DataOps, hybrid and federated ecosystems o advanced AI agent governance, the reactive approach is insufficient. Not because the technical catalogue is not useful, but because it is too late to influence critical decisions.
In our experience, the strongest initiatives are those that combine automated technical visibility with preventive organisational operationalisation.

Inferred technical lineage vs Declarative lineage
Lineage is one of the most common arguments used in the market.
Technical platforms have certain capabilities to infer technical lineage automatically. (WARNING, black magic does not exist and there is a lot of smoke in the market here) from pipelines, queries and transformations. This capability is valuable for understanding technical dependencies and analysing impacts.
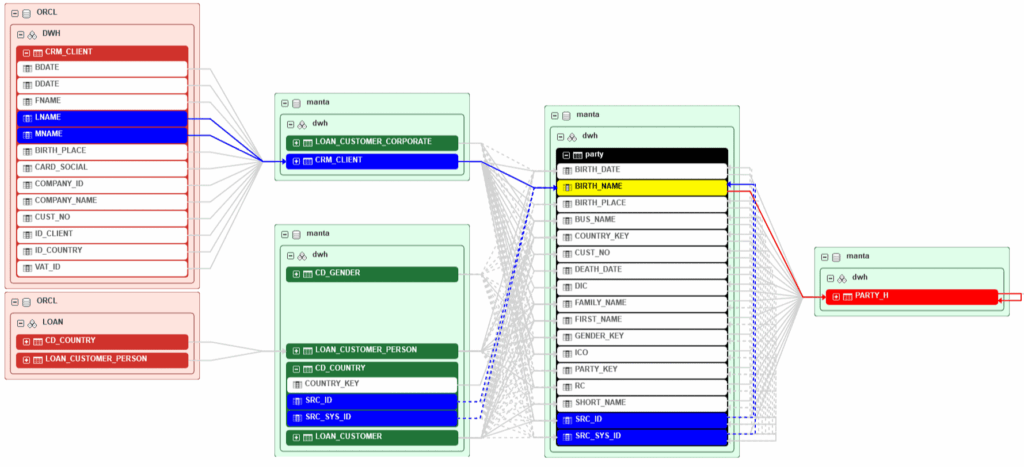
But the inferred technical lineage does not capture organisational or contractual relationships. It does not represent responsibilities, sharing arrangements, approved policies or dependencies between information products from a functional point of view.
Declarative lineage, on the other hand, allows these relationships to be explicitly modelled. It represents how assets are connected from a governance perspective, not just from a technical transformation.
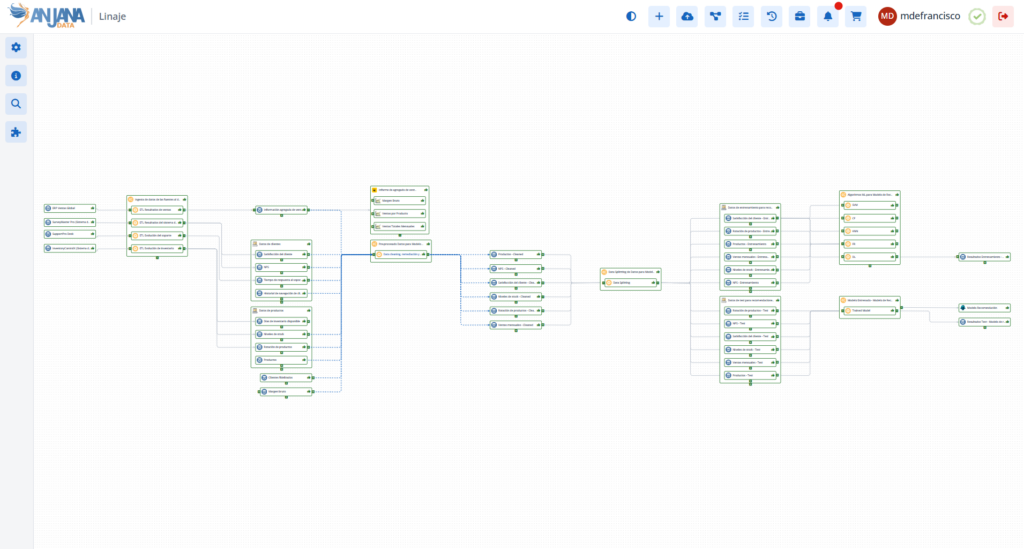
The two approaches are not mutually exclusive. In fact, they must coexist.
The technical lineage lives where it should live: in the technical layer.
Declarative lineage provides a layer of organisational meaning that inferred lineage cannot.
When well thought-out hybrid architectures are designed, both flows are integrated bi-directionally under principles of Active Metadata.
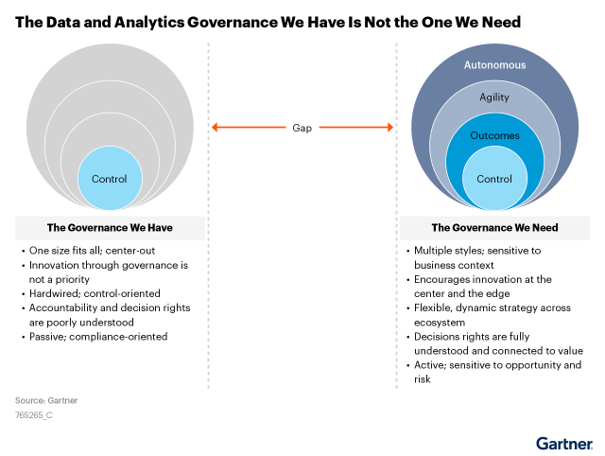
Control-based governance vs. flexible governance
Some organisations interpret governance as a rigid centralised control mechanism. In practice, this generates resistance, friction and slowdown.
But neither does the opposite extreme - purely observational government that only documents what happens - work.
Flexible government combines structure and autonomy. Allows for centralised, federated or hybrid models. Adapts to business groups with multiple organisations. Can coexist in multi-cloud and on-premise environments.
In real-world architectures - with Azure, AWS, GCP, Snowflake, Databricks, Oracle, SQL Server, Cloudera, Denodo and multiple combinations agnosticism is not a luxury, it is a necessity.
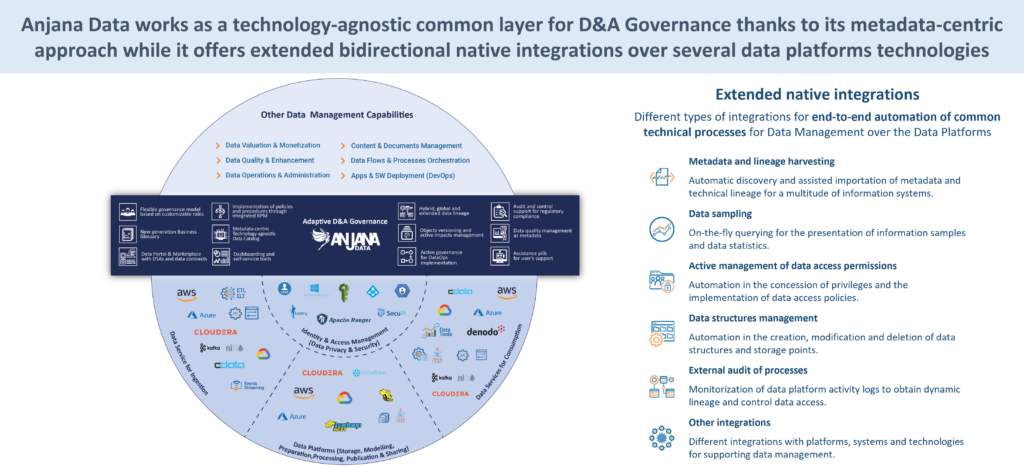
Avoiding lock-in is not just a technological issue. It is also conceptual.
If the governance model is designed around a single technical platform, any future strategic change may force the government to redesign from scratch.
Anticipating cost and maturity
The cost model is another element that is rarely analysed in depth at the outset.
Some technical solutions operate under continuous consumption modelsRecurrent scans, automatic profiling, dynamic classification, change detection. In initial phases, the impact may seem small. As the ecosystem grows, it can become a structural factor.
But beyond the cost, there is the organisational maturity. An overly technical model may work in engineering-focused organisations. It is insufficient when governance must involve business, risk, compliance or AI governance.
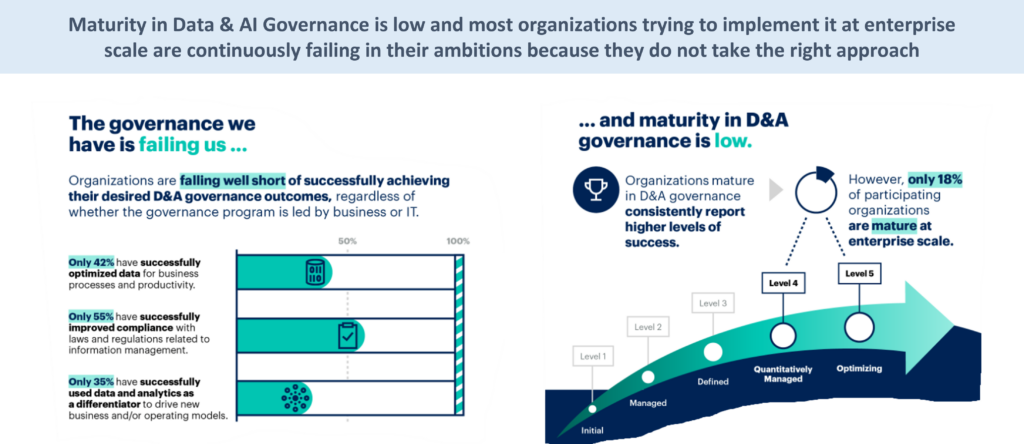
Anticipating these factors is a matter of strategic design, not technical configuration.
Defending the hybrid scenario from the outset
After years of working with real organisations - and seeing both successful implementations and complex rectifications - our conclusion is clear:
The debate is not “Purview or Anjana”.
It is not a “Unity Catalog or governance platform”.
It is not “native or open-source catalogue”.
The debate is about architecture and vision.
The sensible thing to do is to leverage native technical governance where it provides value - discovery, classification, deep technical lineage - and elevate that information to a higher layer of organisational, cross-cutting, agnostic governance.
This hybrid approach:
- Avoid conceptual and technological lock-in.
- It allows for scaling up as maturity grows.
- It integrates technical and functional governance.
- It facilitates the shift from reactive to proactive government.
- It makes the model sustainable in the medium and long term.
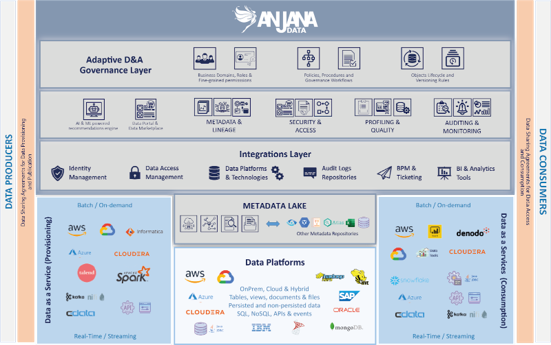
Data Governance & AI Governance
Governing data and governing AI are not exactly the same thing. But neither can they be approached as worlds apart.
Data governance has traditionally focused on quality, semantic definition, accountability, traceability, compliance and access control. Even when limited to the technical level, its focus has been on the lifecycle management of structured assets: tables, pipelines, reports, datasets.
AI governance introduces new dimensions:
-
- Versioning of models.
- Traceability of training datasets.
- Explainability.
- Risk assessment.
- Ethical and regulatory impact.
- Continuous monitoring of behaviour.
- Control of autonomous agents.
-
Management of prompts, embeddings and knowledge sources in generative environments.
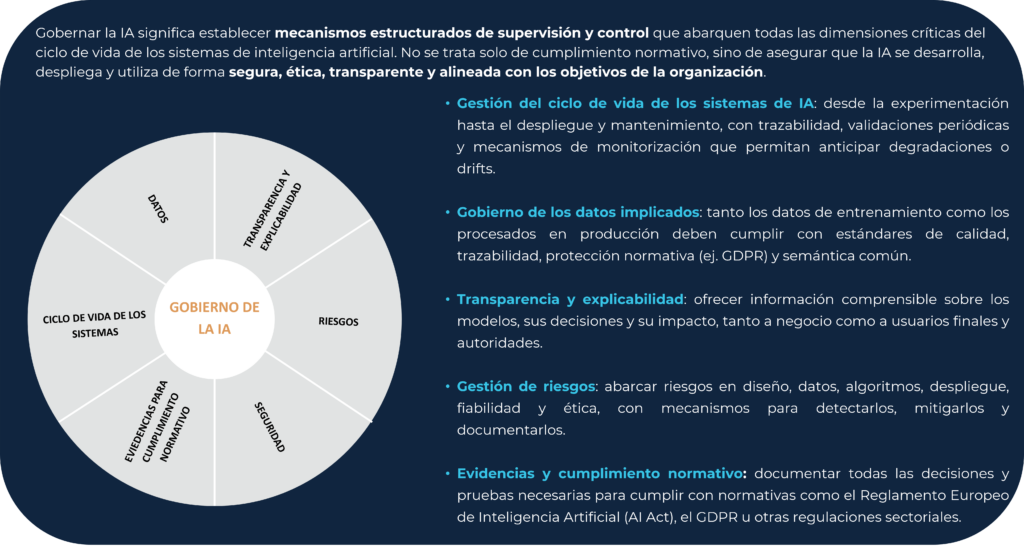
Platform-native technical governance pieces often extend their capabilities to AI from an equally technical perspective. For example, by integrating model metadata, capturing training information or showing technical dependencies between datasets and models within the same technology ecosystem.
This is useful, but insufficient.
Because governing AI is not just about registering that a model exists or knowing which dataset it was trained on. It is to establish who approved it, under what criteria, for what purpose, with what limits of use, under what risk policy and what oversight mechanisms apply.
It is moving from the technical metadata to the organisational context.
Furthermore, an AI model, system or agent does not exist in a vacuum. Depends on dtraining sessions, semantic definitions, quality rules, pAccess policies, responsible domains, contracts of use, etc.
If data governance and AI governance are managed on different platforms, with different organisational models or without real integration, structural problems arise. There are the inconsistencies in responsibilities, the lack of end-to-end traceability, the lack ofifficulties for assessing regulatory impact, the duplication of workflows, the fhigh level of alignment between business and technology and the ross of AI consuming unapproved or uncertified data.
In an environment where AI regulation is growing and where autonomous agents are starting to make operational decisions, this disconnect is not just an inefficiency. It is a strategic risk.
Governing data without governing AI leaves the door open to automated decisions without organisational control.
Governing AI without integrating data governance generates technically traceable but organisationally opaque models.
When data governance and AI governance coexist in the same Data Governance & AI Platform, the approach changes radically.
In an integrated model:
-
An AI model can be declared as an information product.
-
It is associated with a responsible domain.
-
It is formally linked to the approved datasets that feed it.
-
It undergoes approval workflows before deployment.
-
Specific usage contracts are assigned to it.
-
It is connected to regulatory policies.
-
It is integrated into the declarative lineage together with the data assets.
This allows for a complete picture, from raw data to automated decision making. It is not just a technical issue. It is a question of organisational coherence.
In addition, integration brings three key strategic benefits:
- Real end-to-end traceability: From the source data to the model and from the model to the business process that consumes it.
- Clear responsibility: Each asset - data or model - has a domain and associated roles within the same organisational framework.
- Governance ready for autonomous actors: In a world where knowledge consumers are no longer just people but also AI agents, having a unified governance layer allows control over what knowledge is exposed, under what conditions and with what contracts.
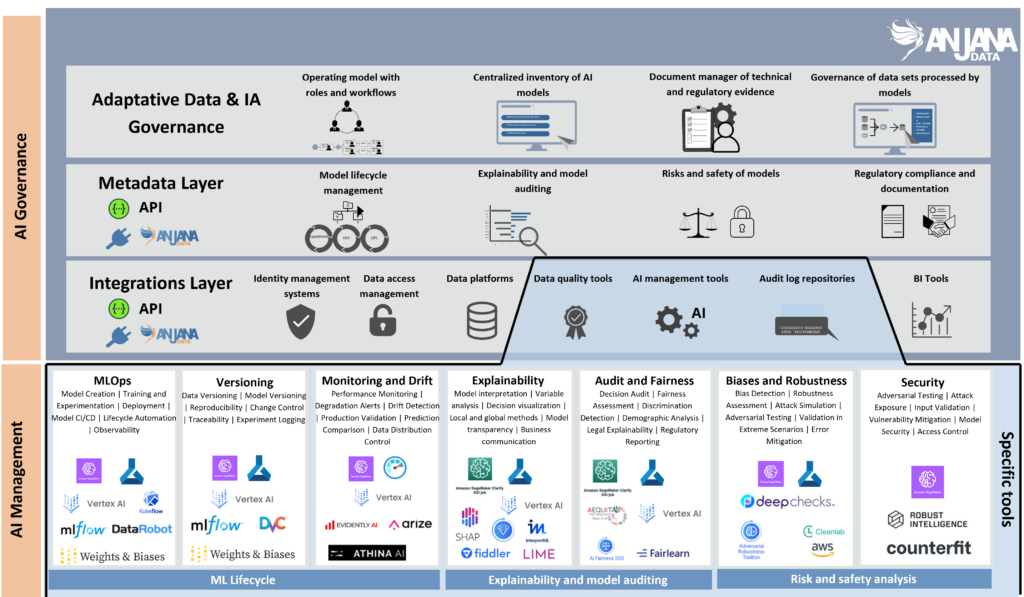
Technical platforms can register models and datasets within their ecosystem. But they are not designed to articulate a cross organisational model that connects data, models, contracts, responsibilities and processes.
A modern AI & Data Governance Platform enables the integration of both worlds under one governance logic.
It is not about adding “AI governance” as an additional module. It is about recognising that AI models are governed information assets and should be part of the same system of responsibilities, policies and contracts as data.
Here the central message makes sense again: Anjana does not compete with the native technical governance of Data & AI Platforms. It elevates it to a higher layer of comprehensive, cross-cutting, agnostic and business-oriented governance.
And in the current context, that integration between data governance and AI governance is not optional. It is the only coherent approach for organisations that want to scale their use of artificial intelligence without taking unnecessary risks.
From the Data Catalog to the Knowledge Marketplace: the real competitive advantage
So far we have talked about visibility, control and architecture. But there is an even more strategic question that few organisations ask themselves at the outset:
What do we really want to govern for?
The answer should not just be to comply with regulations or to have the inventory in order. The real goal is to turn data and AI into reusable, sharable and exploitable knowledge in a controlled way.
If data governance and AI governance are integrated in the same organisational logic, something very interesting happens. The conversation is no longer purely defensive -monitoring, compliance, risk mitigation and becomes strategic.
Because when data and models are in a state of flux, thee formally declared as governed assets, aand responsible persons, vinculcated by declarative lineage, sujects to workflows and policies, regulated by contracts of use and are auditable throughout their life cycle, en then the organisation does not only control. It can also activating knowledge in a secure and scalable way.
And it is at this point that the next evolutionary level appears. We are no longer talking about a catalogue. We are not just talking about government. We are talking about Knowledge Marketplace.
For years, the market has spoken of the Data Marketplace as a repository for datasets. But that view is limited. A Knowledge Marketplace does not just publish tables; it publishes complete information products, integrating data, semantic context, quality rules, usage policies, responsible parties, contracts and traceability.
It is not just data that is shared. You share governed business knowledge.
And this cannot be built solely on a technical catalogue. A catalogue can show that a dataset exists. But it cannot, on its own, declare it as an approved product, associate it with a responsible domain, establish usage contracts or automate the granting of access under organisational rules.
The actual realisation of a Knowledge Marketplace requires a modern Data Governance & AI Platform, capable of converting technical assets into governed products.
Read our article explaining the evolution from Data Marketplace to Knowledge Marketplace here.
This transforms the democratisation of knowledge into a regulated, traceable process aligned with the governance model.
And it is even more relevant in today's context. Knowledge consumers are no longer just people. They are also AI models, autonomous agents and automated systems that need to access business knowledge in a standardised, secure and governed way.
These actors cannot interpret organisational informalities or manually navigate technical catalogues. They need context, contracts and clear rules.
In this scenario, the Knowledge Marketplace becomes the icing on the cake. It is the natural result of having designed the right governance architecture from the start.
And it is increasingly the source of real competitive advantage.
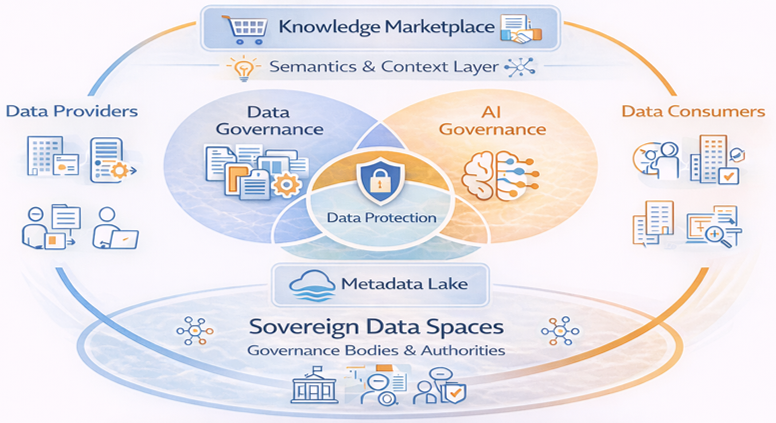
Conclusion. From catalogue to real government
To govern is not to catalogue. Technical governance is not a substitute for organisational governance. Inferred lineage is not a substitute for declarative accountability. Reactive control does not equal preventive design.
Democratising knowledge does not mean opening access without control. It means doing so in a governed, contextualised, secure and aligned manner with clear responsibilities.
And governing AI is not just about registering models. It is to ensure that each automated decision is backed by approved data, defined policies and explicit usage contracts.
Anjana does not compete with the native technical governance of Data & AI Platforms. It elevates it to a higher layer of comprehensive, cross-cutting, agnostic and business-oriented governance.
A layer that allows data governance and AI governance to be integrated under the same organisational logic. A layer that enables the controlled democratisation of business knowledge. A layer that enables individuals and autonomous agents to access knowledge in a standardised, secure and traceable way.
In a market increasingly driven by data, AI and automation, the difference is not who has the most metadata. It is in who is able to transform data and models into governed and activatable knowledge. And that difference is strategic.