¿Problemas con tus datos? Necesitas DataOps*

[*DataOps = Gobierno del Dato proactivo y preventivo]
El manifesto DataOps aglutina una serie de prácticas que se publicaron en 2017 para intentar dar solución a problemas relacionados con la ineficiencia de los procesos de generación y tratamiento de datos, así como con la calidad de los mismos en relación a los errores de inconsistencia e incoherencias entre los datos. Pese a lo que se pueda pensar en un inicio, DataOps no es solo DevOps para datos, aunque sí que la idea parte de aplicar al ámbito de los datos este concepto que está muy extendido e implantado en el campo del desarrollo y operación del software.
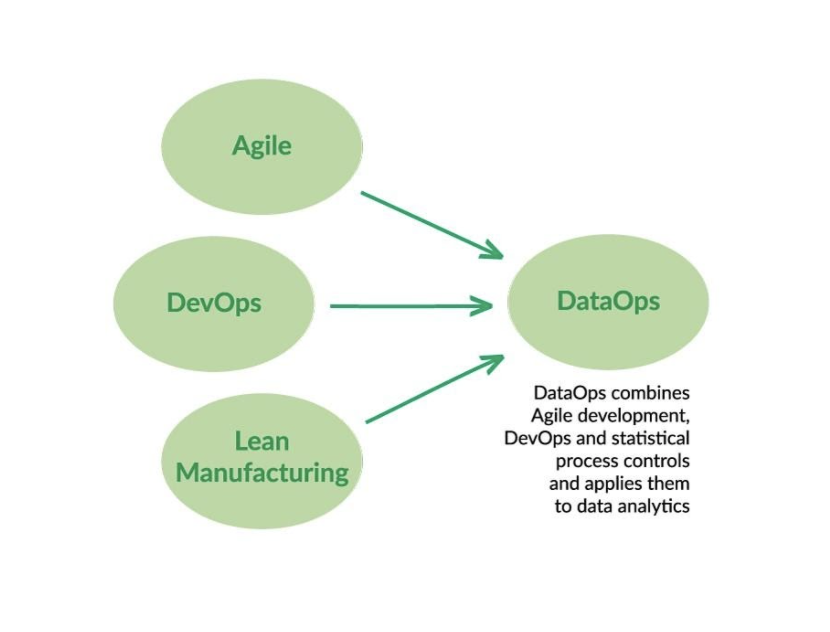 Lo que dice el manifiesto DataOps, complementado con la iniciativa que salió en 2018 llamada ‘La filosofía del DataOps’, es que DataOps es una combinación entre las metodologías ágiles, los conceptos DevOps y todo lo que se conoce como el Lean Manufacturing. De esta forma, además de los conceptos propios de DevOps, también se incorporan conceptos de gestión más relacionados con las metodologías ágiles y otros conceptos más cercanos al mundo de la industria y de los procesos de la fabricación y producción.
Lo que dice el manifiesto DataOps, complementado con la iniciativa que salió en 2018 llamada ‘La filosofía del DataOps’, es que DataOps es una combinación entre las metodologías ágiles, los conceptos DevOps y todo lo que se conoce como el Lean Manufacturing. De esta forma, además de los conceptos propios de DevOps, también se incorporan conceptos de gestión más relacionados con las metodologías ágiles y otros conceptos más cercanos al mundo de la industria y de los procesos de la fabricación y producción.
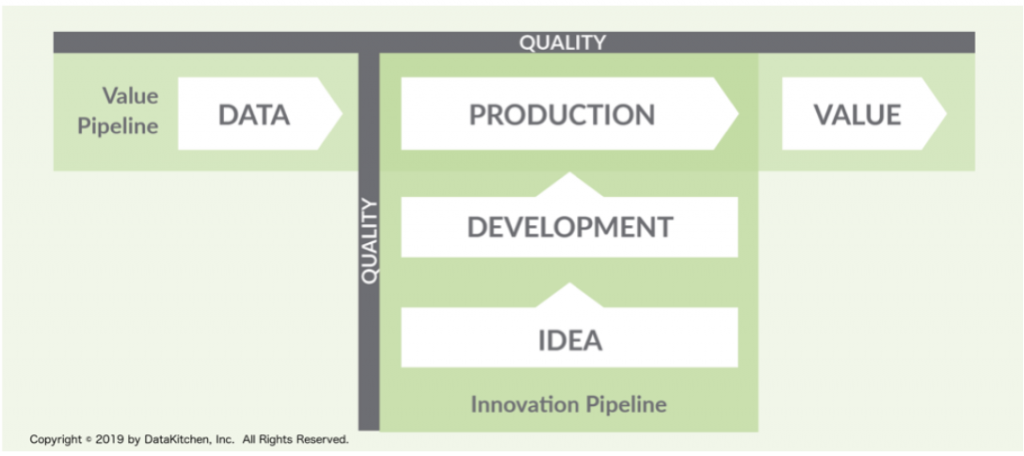
Así pues, la finalidad de DataOps consiste en gestionar de forma ágil toda la parte de DevOps (idea, desarrollo, producción del software) junto con la cadena de valor y el ciclo de vida de los datos. En este contexto, DataOps son una serie de técnicas, metodologías, herramientas y procesos que puestos en conjunto ayudan a la organización, o a un proyecto concreto, a poder extraer un mayor valor de los datos gracias a la automatización de los procesos que ocurren en el ciclo de vida del dato. Todo ello con el objetivo de poder tener una mayor rentabilidad de los proyectos e iniciativas de analítica de datos.
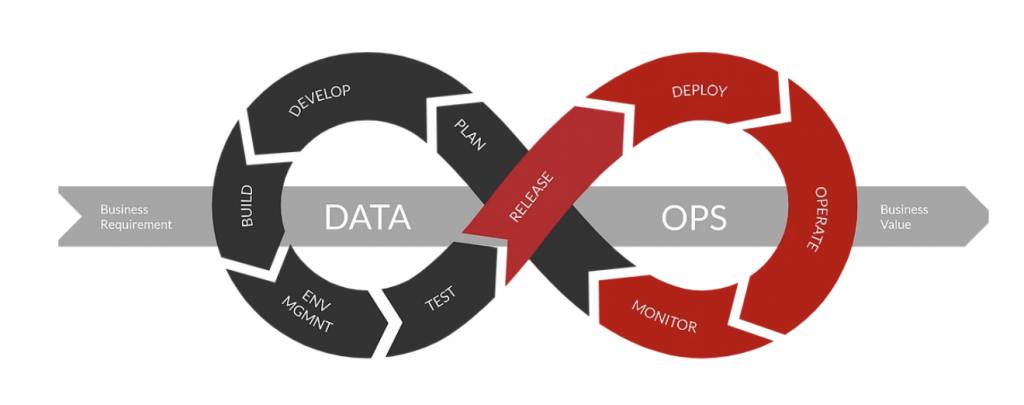
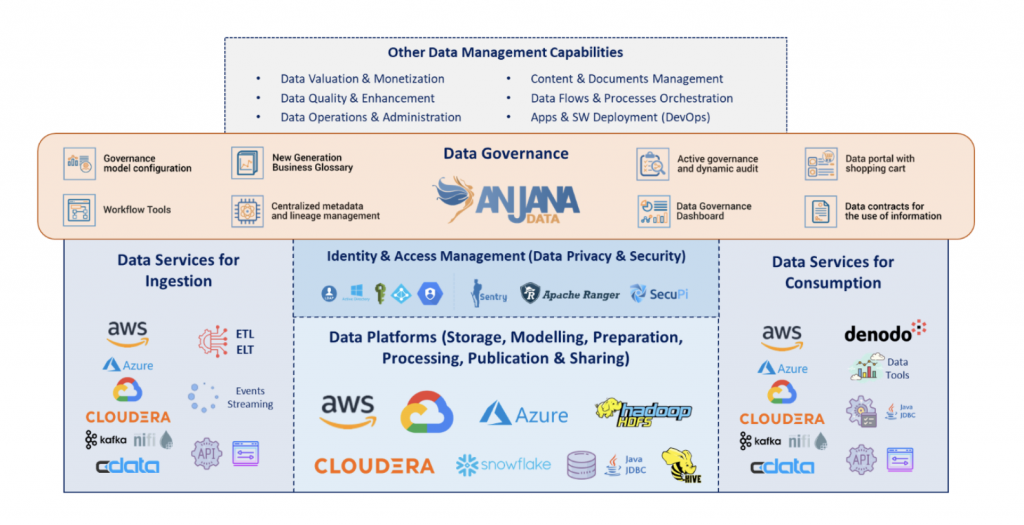
Desde el punto de vista de arquitectura funcional, una plataforma DataOps persigue:
- Integrar datos de diferentes fuentes, automatizando su ingesta, carga y disponibilización.
- Controlar el almacenamiento de datos con sus distintas versiones a lo largo del tiempo, historificando la información y los procesos de transformación de datos.
- Contar con una gestión centralizada de los metadatos que sirva no sólo para conocer la información disponible sino también para activar y configurar los procesos de la plataforma.
- Tener controlada toda la gestión relativa a solicitud, autorización y permisos de acceso a datos para consumo y explotación.
- Y, por último, aplicar mecanismos y técnicas de analítica, reporte y dashboarding para hacer una monitorización y un seguimiento de lo que está pasando en toda la plataforma.
Todo ello, operado por un equipo de DataOps para facilitar a los productores y consumidores de información la compartición de datos y desarrollo de proyectos e iniciativas en la plataforma.
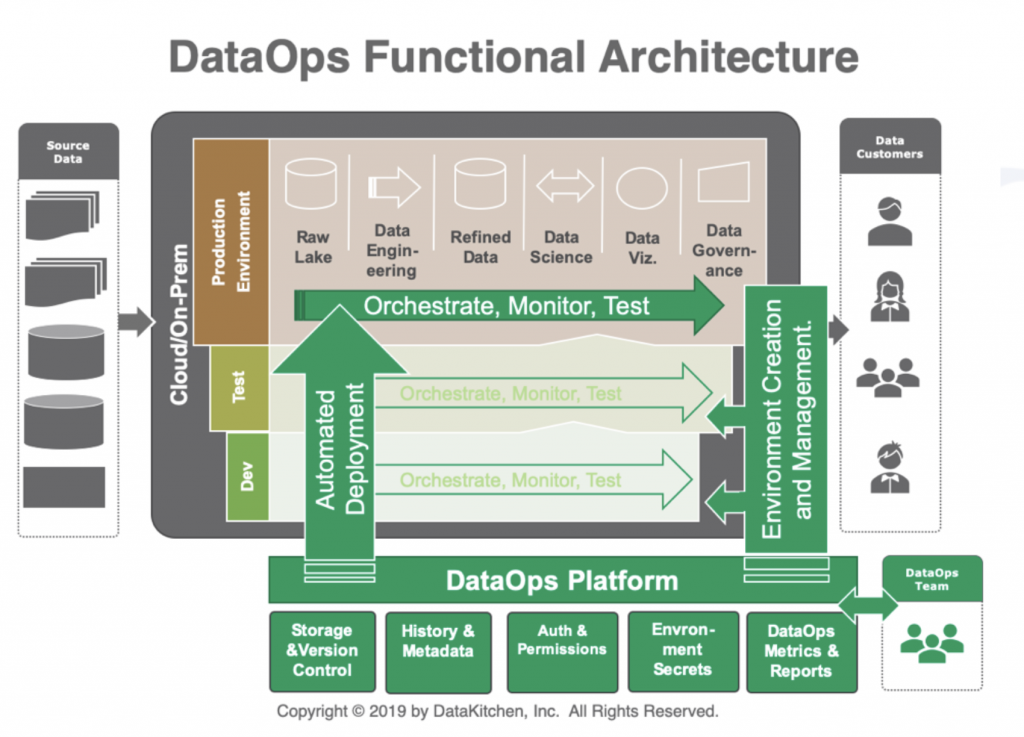
Adicionalmente, por un lado, se debe buscar el encaje con la automatización de los despliegues de software para lograr una integración continua, mientras que por otro lado, en relación al flujo de los datos, se deben orquestar, probar, automatizar y monitorizar los pipelines de datos dentro de la propia plataforma: como siempre, moviendo los datos desde zonas donde la información está en bruto, hasta que se va tratando, refinando y enriqueciendo en capas posteriores para finalmente poder realizar analítica sobre la información en las capas de explotación.
En este contexto, el Gobierno del Dato se posiciona en numerosas ocasiones al final de la cadena de valor y del ciclo de vida del dato, lo cual es algo totalmente erróneo y vamos a explicar por qué.
A lo largo de toda la cadena de valor del dato coexisten multitud de roles que van a tener que colaborar entre sí, desde desarrolladores hasta usuarios de negocio, pasando por arquitectos, equipos de operaciones, técnicos de sistemas, etc. Por ello, es necesario implantar metodologías de gestión (en este caso ágiles) como un principio básico y con una gestión del cambio continuada, partes fundamentales en el Gobierno del Dato. Sólo así podremos finalmente lograr la automatización de procesos técnicos que nos aporten una mayor eficiencia y seguridad, siendo uno de los principales objetivos que persigue DataOps.
Adicionalmente, para llegar a cubrir los objetivos de DataOps, es necesario tener un control completo sobre el ciclo de vida del dato, separar la información en capas lógicas y saber exactamente cómo fluye la misma a lo largo del ecosistema de datos en conjunto (linaje y trazabilidad), así como plantear el encaje del ciclo de vida del dato con el ciclo de vida del software. Por último, tampoco se debe olvidar la importancia de lograr una integración total con la arquitectura técnica, ya que sin integrar las diferentes piezas técnicas de la misma, no se podrán automatizar los correspondientes procesos de datos. Y, al fin y al cabo, todo esto son partes en las que el Gobierno del Dato tiene mucho que aportar.
Finalmente, para lograr una integración y automatización completa de los procesos, se deben incorporar tres capas de gestión imprescindibles:
- Gestión de la demanda en proyectos de datos: cambios sobre la información existente, nuevos casos de uso y explotación de información, captura e ingesta de nuevos datos, …
- Gestión de metadatos y versiones de las estructuras de datos, ya que al final los metadatos van a ser la pieza central que va a permitir automatizar muchas funciones alrededor de este concepto de DataOps.
- Gestión de los permisos de acceso al dato de forma centralizada, para que al final se pueda saber quién consume qué información y para qué.
Por lo tanto, después de haber desgranado todo lo necesario para alcanzar la implantación de un modelo DataOps, podemos entenderlo como la evolución natural del Gobierno del Dato. Un Gobierno del Dato por diseño (governance-first o governance-by-design), proactivo y preventivo que se sitúa al principio de la cadena de valor del dato y que acompaña a los diferentes intervinientes en todo el ciclo de vida del dato, siendo eje central de los procesos, y aportando en todo momento una visión global que nos permitirá alcanzar la efectividad y eficiencia perseguidas.
Pese a lo que se pueda pensar en un primer momento, el Gobierno del Dato proactivo y preventivo situado al principio de la cadena de valor del dato trata de reducir al máximo la burocracia con políticas y procedimientos claros y concisos, aportando flexibilidad y agilidad a los procesos (sobre todo de gestión) y permitiendo así maximizar las sinergias entre los diferentes proyectos y casos de uso, promoviendo la reutilización tanto de información como de procesos existentes en la plataforma. En definitiva, gracias a esta visión del Gobierno del Dato, estamos habilitando una ventanilla única de entrada al ecosistema de datos para todos los stakeholders de datos aplicando además un enfoque colaborativo para:
- Integración con la gestión de la demanda.
- Integración entre tecnologías y piezas del ecosistema.
- Automatización de procesos técnicos comunes.
- Enfoque incremental e iterativo por casos de uso.
- Democratización y autoservicio gobernado de datos.
- Monitorización para la mejora continua.
Todo esto sólo es posible construyendo un repositorio único y centralizado de metadatos como pieza central del ecosistema de datos y abstrayendo el gobierno y la gestión de los datos de las tecnologías y plataformas que subyacen ya que el Gobierno del Dato tiene un foco muy distinto que el de las tecnologías de captura, almacenamiento, tratamiento, procesamiento y explotación de los datos, mucho más preocupadas por el rendimiento en los procesos que por la correcta gestión de los datos.
Por último, complementando este repositorio con un lenguaje común y único basado en el conocimiento del negocio y de la organización (lo que se conoce como Glosario de Negocio) nos permitirá a su vez construir un mapa semántico de activos de información (incorporando las correspondientes taxonomías) que hará que podamos acercar el dato cada vez más a los usuarios de negocio y seguir tendiendo puentes con los equipos técnicos.
Si quieres conocer algunos casos prácticos de DataOps puedes ver esta ponencia y si quieres saber cómo puedes conseguir implantar un modelo de DataOps gracias a Anjana Data, escríbenos y estaremos encantados de ayudarte 🙂