Problems with your data? You need DataOps*

[*DataOps = Proactive and preventative Data Governance]
The DataOps manifesto brings together a series of practices that were published in 2017 to try to solve problems related to the inefficiency of data generation and processing processes, as well as the quality of data in relation to inconsistency errors and inconsistencies between data. Despite what one might think at first, DataOps is not just DevOps for data, although the idea is to apply this concept, which is very widespread and implemented in the field of software development and operation, to the field of data.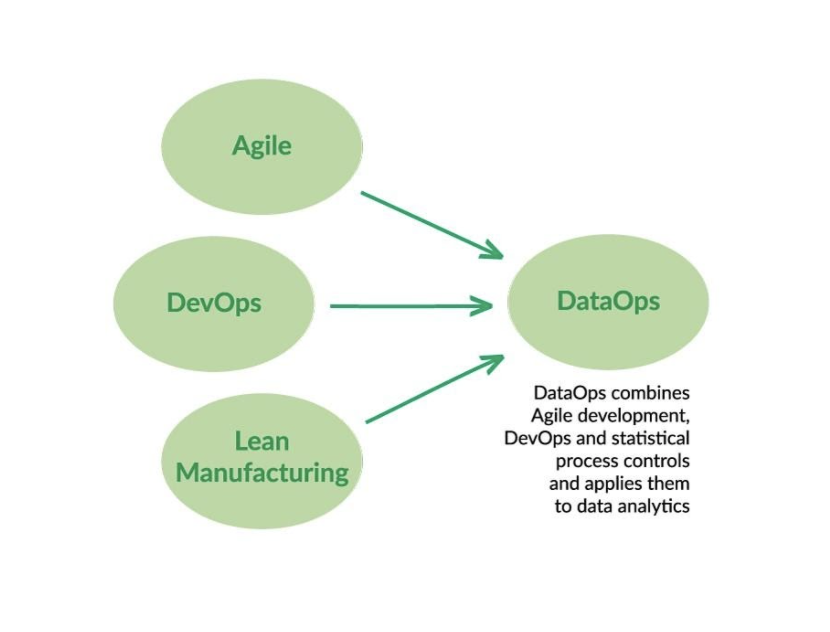 What the DataOps manifesto says, complemented by the initiative that came out in 2018 called ‘The DataOps Philosophy’, is that DataOps is a combination of agile methodologies, DevOps concepts and everything known as Lean Manufacturing.. In this way, in addition to the concepts of DevOps, it also incorporates management concepts more related to agile methodologies and other concepts closer to the world of industry and manufacturing and production processes.
What the DataOps manifesto says, complemented by the initiative that came out in 2018 called ‘The DataOps Philosophy’, is that DataOps is a combination of agile methodologies, DevOps concepts and everything known as Lean Manufacturing.. In this way, in addition to the concepts of DevOps, it also incorporates management concepts more related to agile methodologies and other concepts closer to the world of industry and manufacturing and production processes.
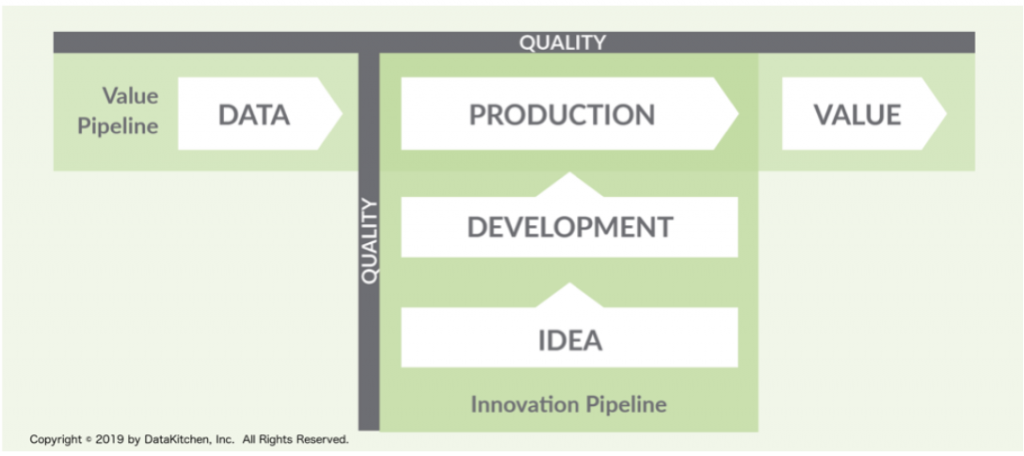
Thus, the purpose of DataOps is to manage in an agile way the entire DevOps part (idea, development, production of the software) together with the value chain and the life cycle of the data. In this context, DataOps is a series of techniques, methodologies, tools and processes that together help the organisation, or a specific project, to extract greater value from the data thanks to the automation of the processes that occur in the data lifecycle.. All of this with the aim of achieving greater profitability from data analytics projects and initiatives.
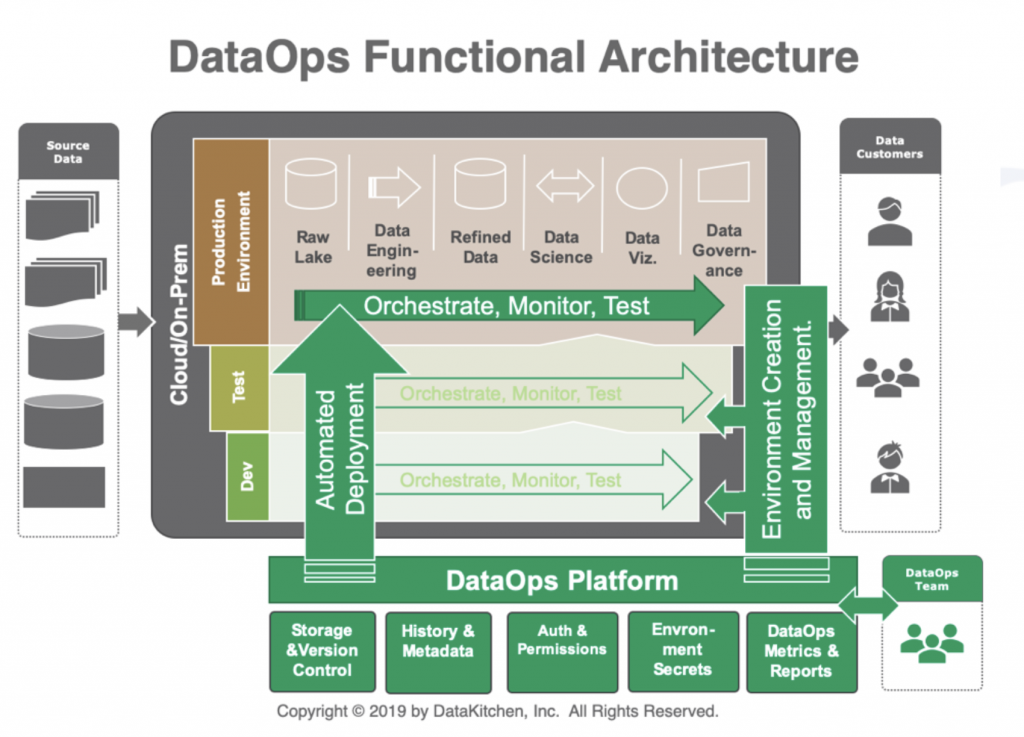
From a functional architecture point of view, a DataOps The platform aims to:
- Integrate data from different sources, automatising their ingestion, loading and availability.
- Control the storage of data with its different versions over time, historicising the information and data transformation processes.
- To have a centralised management of metadata that serves not only to know the available information but also to activate and configure the platform’s processes.
- To have under control all the management related to the request, authorisation and access permissions to data for consumption and exploitation.
- And, finally, to apply analytical, reporting and dashboarding mechanisms and techniques to monitor and track what is happening throughout the platform.
All this, operated by a DataOps team to facilitate the sharing of data and the development of projects and initiatives on the platform for producers and consumers of information.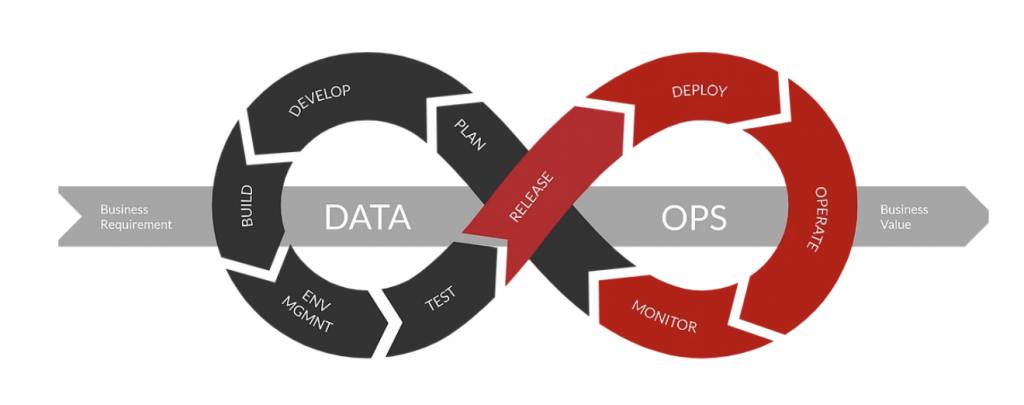 Furthermore, on the one hand, it is necessary to seek alignment with the automatisation of software deployments to achieve continuous integration, while on the other hand, in relation to data flow, Data pipelines must be orchestrated, tested, automated, and monitored. within the platform itself: as always, moving data from areas where the information is raw, until it is treated, refined and enriched in subsequent layers to finally be able to perform analytics on the information in the layers of exploitation.
Furthermore, on the one hand, it is necessary to seek alignment with the automatisation of software deployments to achieve continuous integration, while on the other hand, in relation to data flow, Data pipelines must be orchestrated, tested, automated, and monitored. within the platform itself: as always, moving data from areas where the information is raw, until it is treated, refined and enriched in subsequent layers to finally be able to perform analytics on the information in the layers of exploitation.
In this context, Data Governance is often positioned at the end of the value chain and the data lifecycle, which is entirely incorrect, and we will explain why.
Throughout the entire data value chain, a multitude of roles coexist that will have to collaborate with each other, from developers to business users, including architects, operations teams, systems technicians, etc. Therefore, it is necessary to implement management methodologies (in this case agile) as a basic principle and with continuous change management, fundamental parts of Data Governance. Only in this way can we finally achieve the automation of technical processes that provide us with greater efficiency and security, which is one of the main objectives pursued by DataOps.
In addition, to achieve DataOps objectives, it is necessary to have complete control over the data lifecycle, to separate the information into logical layers and to know exactly how it flows through the data ecosystem as a whole (lineage and traceability), as well as to consider how the data lifecycle fits in with the software lifecycle. Finally, the importance of achieving full integration with the technical architecture should not be forgotten either, as without integrating the different technical parts of the architecture, it will not be possible to automate the corresponding data processes. And, after all, these are all parts where Data Governance you have a lot to contribute.
Finally, to achieve complete integration and automation of processes, tres niveles esenciales de gestión must be incorporated:
- Gestión de la demanda en proyectos de datos: changes to existing information, new use cases and exploitation of information, capture and ingestion of new data, …
- Gestión de metadatos y versiones de estructuras de datos, since metadata will be the central piece that will enable the automation of many functions around this DataOps concept.
- Centralised management of data access permissions, so that in the end it is possible to know who consumes what information and for what purpose.
Therefore, after having unpacked all that is necessary to achieve the implementation of a DataOps model, we can understand it as the natural evolution of Data Governance. Data Governance by design (governance-first or governance-by-design), proactive and preventive, which is located at the beginning of the data value chain and which accompanies the different stakeholders throughout the data life cycle, being the central axis of the processes, and providing at all times a global vision that will allow us to achieve the desired effectiveness and efficiency.
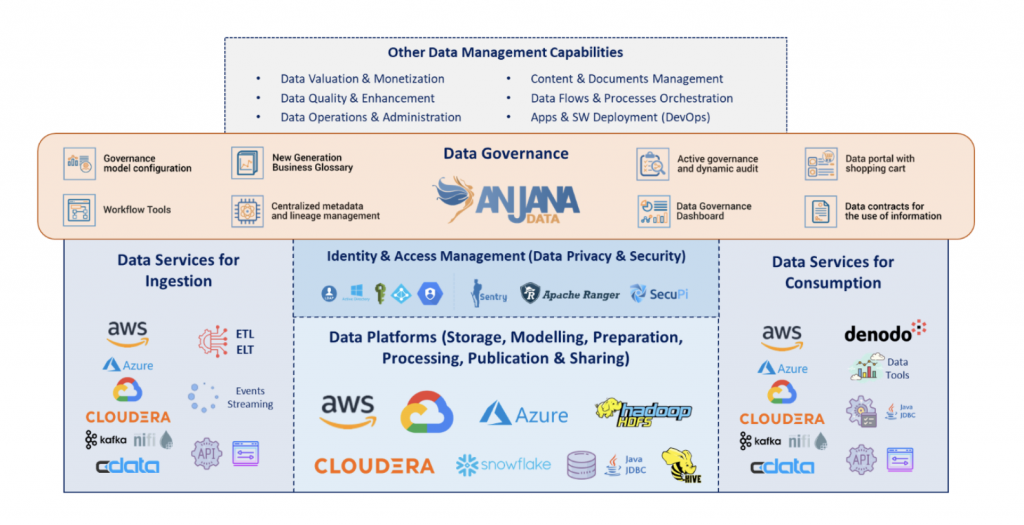
Despite what one might think at first, the proactive and preventative Data Governance situated at the beginning of the data value chain attempts to reduce bureaucracy as much as possible with clear and concise policies and procedures, providing flexibility and agility to the processes (especially management) and thus maximising synergies between the different projects and use cases, promoting reuse of both information and existing processes in the platform. In short, thanks to this vision of Data Governance, Estamos habilitando un único punto de entrada al ecosistema de datos. for all data stakeholders by applying a collaborative approach to:
- Integration with demand management.
- Integration between technologies and parts of the ecosystem.
- Automation of common technical processes.
- Incremental and iterative approach by use cases.
- Democratisation and data-driven self-service.
- Monitoring for continuous improvement.
All this is only possible by construir un solo, centralised metadata repository as the centrepiece of the data ecosystem and abstracting data governance and management from the underlying technologies and platforms, as Data Governance has a very different focus than data capture, storage, treatment, processing and exploitation technologies, which are much more concerned with process performance than with proper data management.
Finally, complementing this repositorysitory with a common and unique language based on the knowledge of the business and the organisation (known as Business Glossary) will in turn allow us to build a semantic map of information assets (incorporating the corresponding taxonomies) that will enable us to bring the data ever closer to the business users and continue to build bridges with the technical teams.
If you want to know some praticable instances of DataOps you can see this presentation and if you want to know how you can implement a DataOps model thanks to Anjana Data, write to us and we will be happy to assist you 🙂