Anjana Data V2.0: improvements in usability and new customisation capabilities of the CORE metamodel

Anjana Data launches its version 2.0 with capability improvements and functionalities and new configuration, adaptation, and customisation features in order to implement agile, flexible, proactive, and collaborative data governance.
The year 2020 has brought for Anjana Data an evolution in terms of its functionalities and features, both technical and usability, which provide a differential value in the final objective of achieving effective and efficient Data Governance, necessary to turn data into a strategic asset of any organisation.
Following the same vision and philosophy of the collaborative approach focused on metadata, we have worked in four main ways:
- Facilitating the consumption of information by the different participants and extending the interaction capacities between them with improved usability
- To make the CORE metamodel more flexible so that it can be adapted to the needs of the organisation, offering new extension and adaptation capabilities.
- Expand the configuration and maintenance capabilities of the governance model
- Technology integration with different platforms to offer end-to-end automation and increased interoperability capabilities through APIs.
Below we detail the new capability improvements that Anjana Data’s version 2.0 offers:
UX and UI improvements
With the premise of delivering a version that is easy to use and fulfils the function of being the central solution for data governance in an organisation, Anjana Data presents improvements in the user experience and interface through substantial changes in different screens of the application such as the Data Portal, the detail views of the objects, the lineage graphs, the management of the workflows and the Administration Panel.
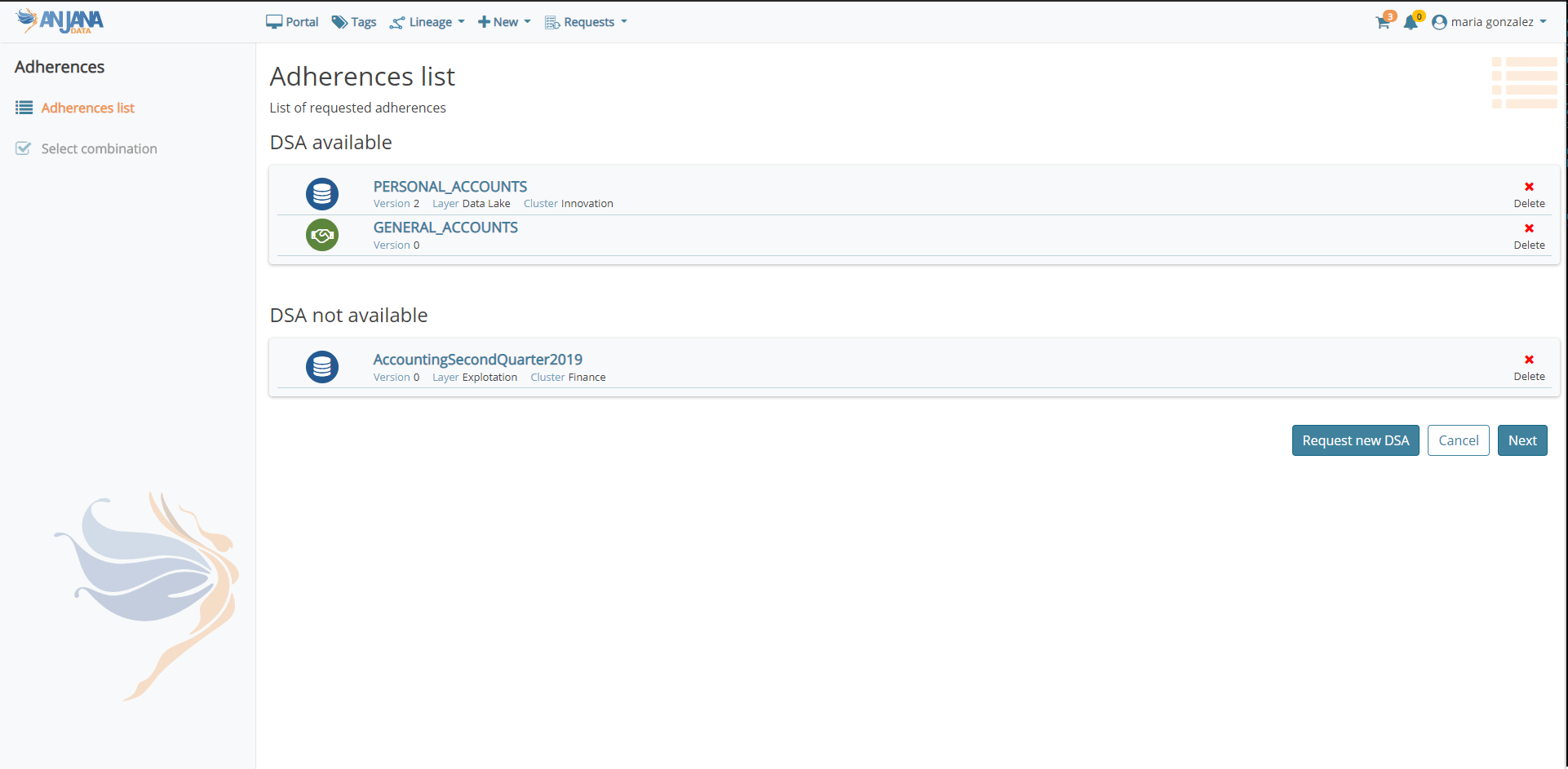
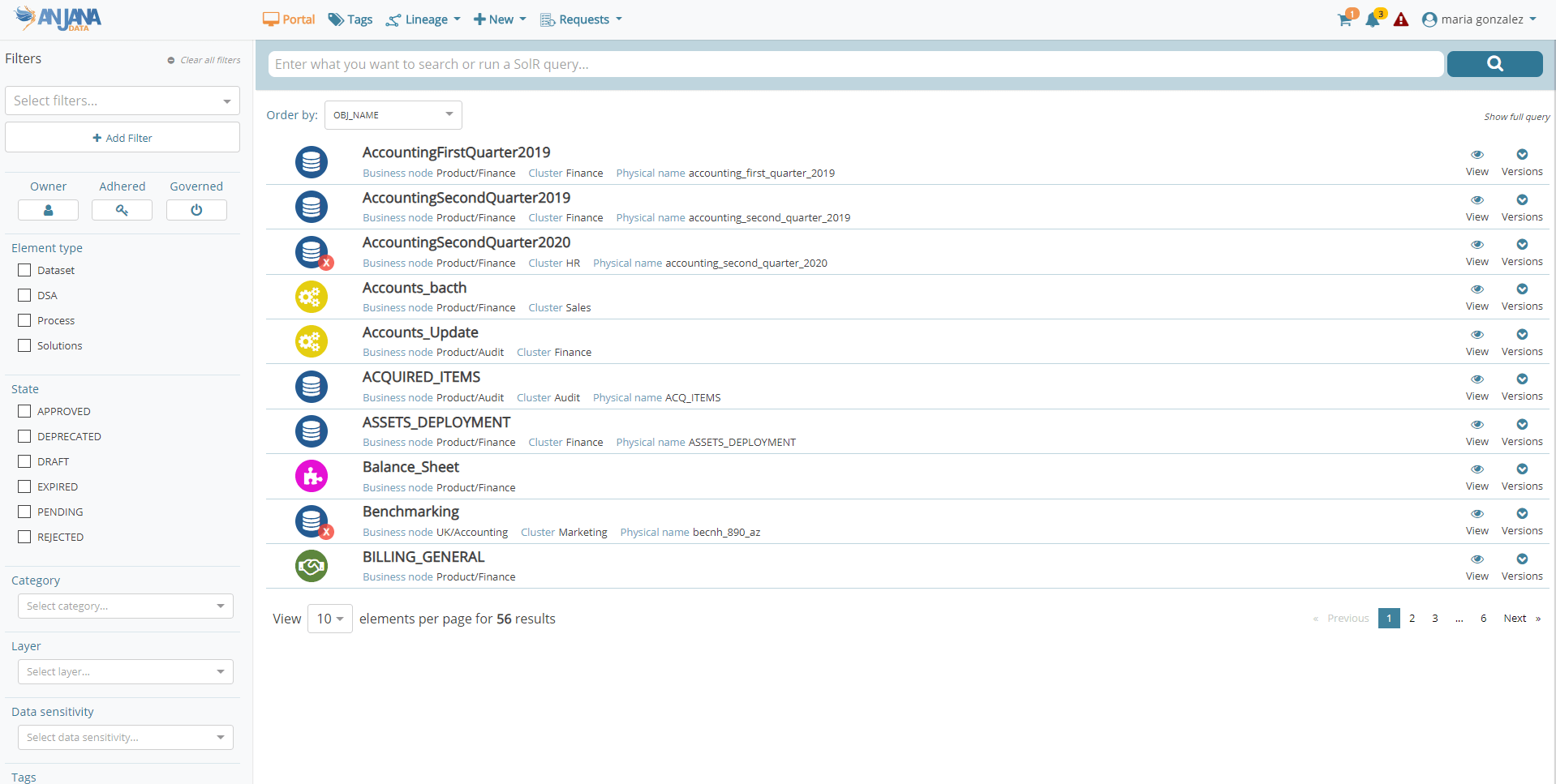
The Data Portal includes a more advanced and optimised search engine, dynamic filters, new more intuitive icons and more condensed information to facilitate the search and discovery of governed data assets. In addition, the solution now allows you to visualise the properties of the objects with different views to adapt to the user's consumption needs and also simplifies the process of massive loading of objects both from Excel and by automatic import using the available connectors or the API.
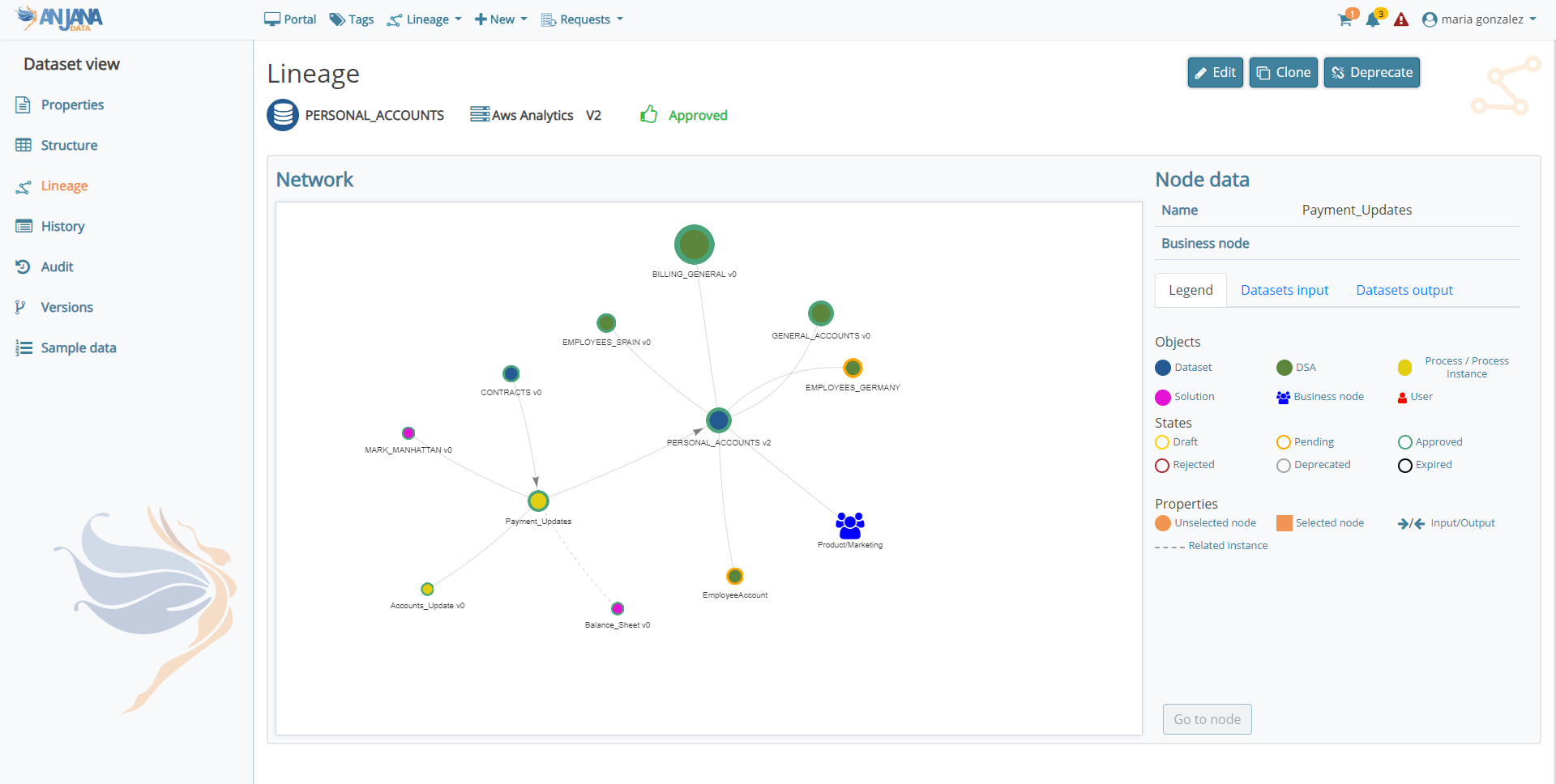
In relation to the lineage and traceability graphs, new elements are included to facilitate their interpretation, such as the representation of users adhering to DSAs, directional arrows that indicate the direction of the data flow (dataset input >> process/instance >> dataset output) and the differentiation of related process instances with respect to the ones specific to the solutions.
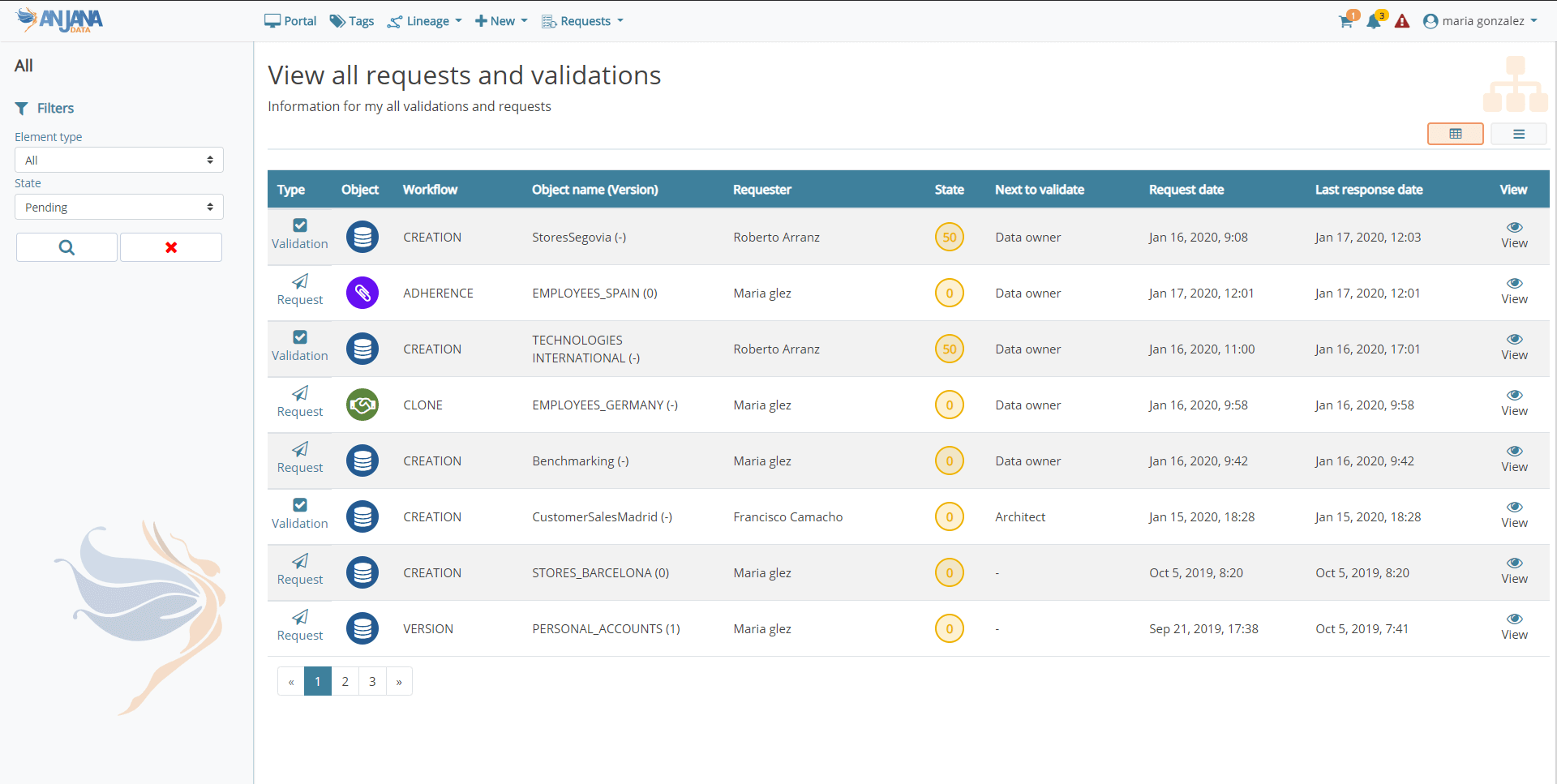
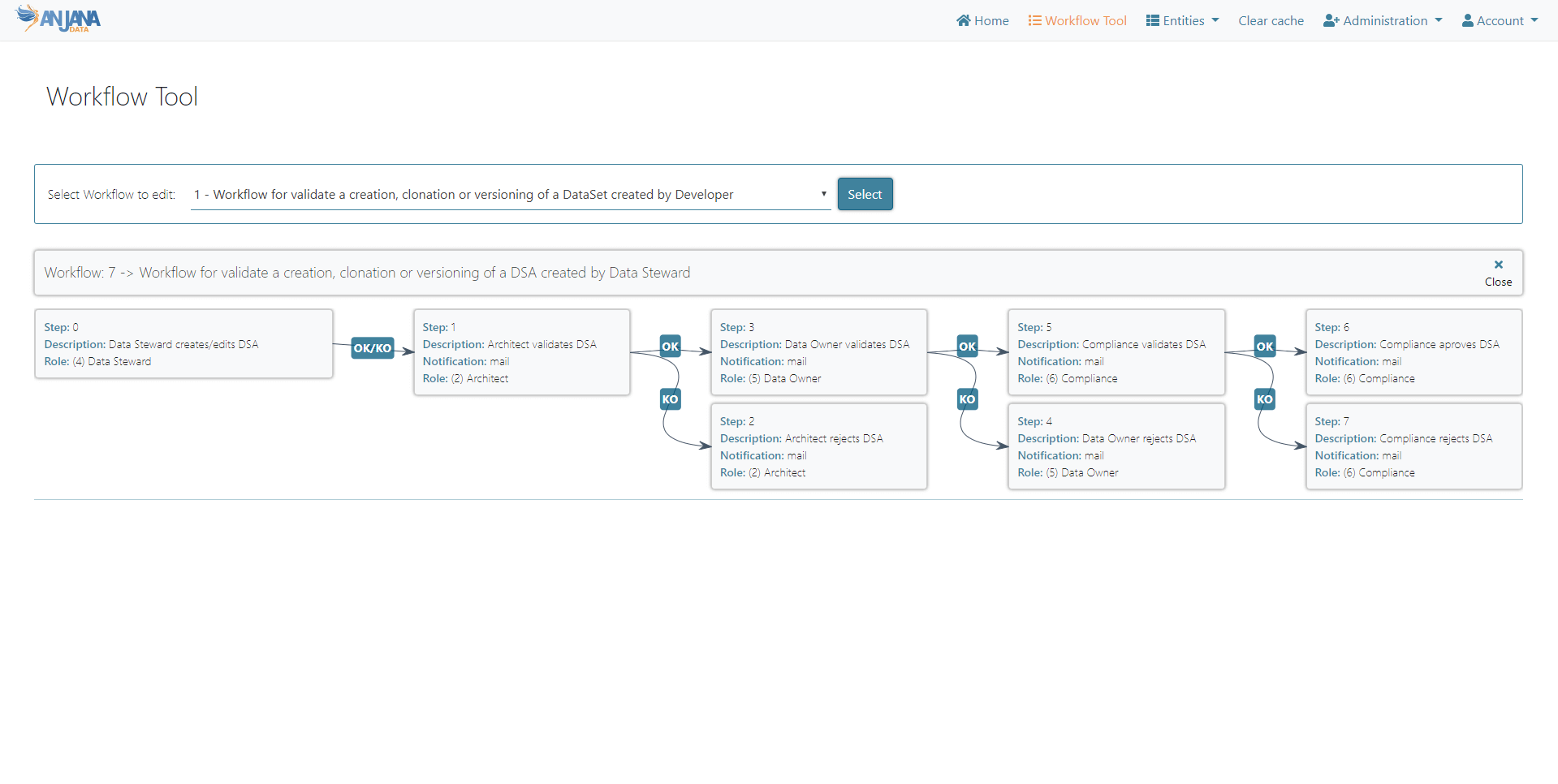
As for the visualisation of workflows, new ways of consuming the information are also available in order to have a global vision of the requests, facilitating their follow-up and offering the possibility of having all the detail available at the click of a button.
Finally, to facilitate the configuration and administration of the solution, a new front panel is presented from which all the parameterisation, management and maintenance tasks of the government model can be carried out graphically (business areas, roles, users, permissions, workflows, taxonomies, passive vs. active government, connections, parameter catalogues, tags, etc.).
Capability improvements: CORE 2.0 Metamodel
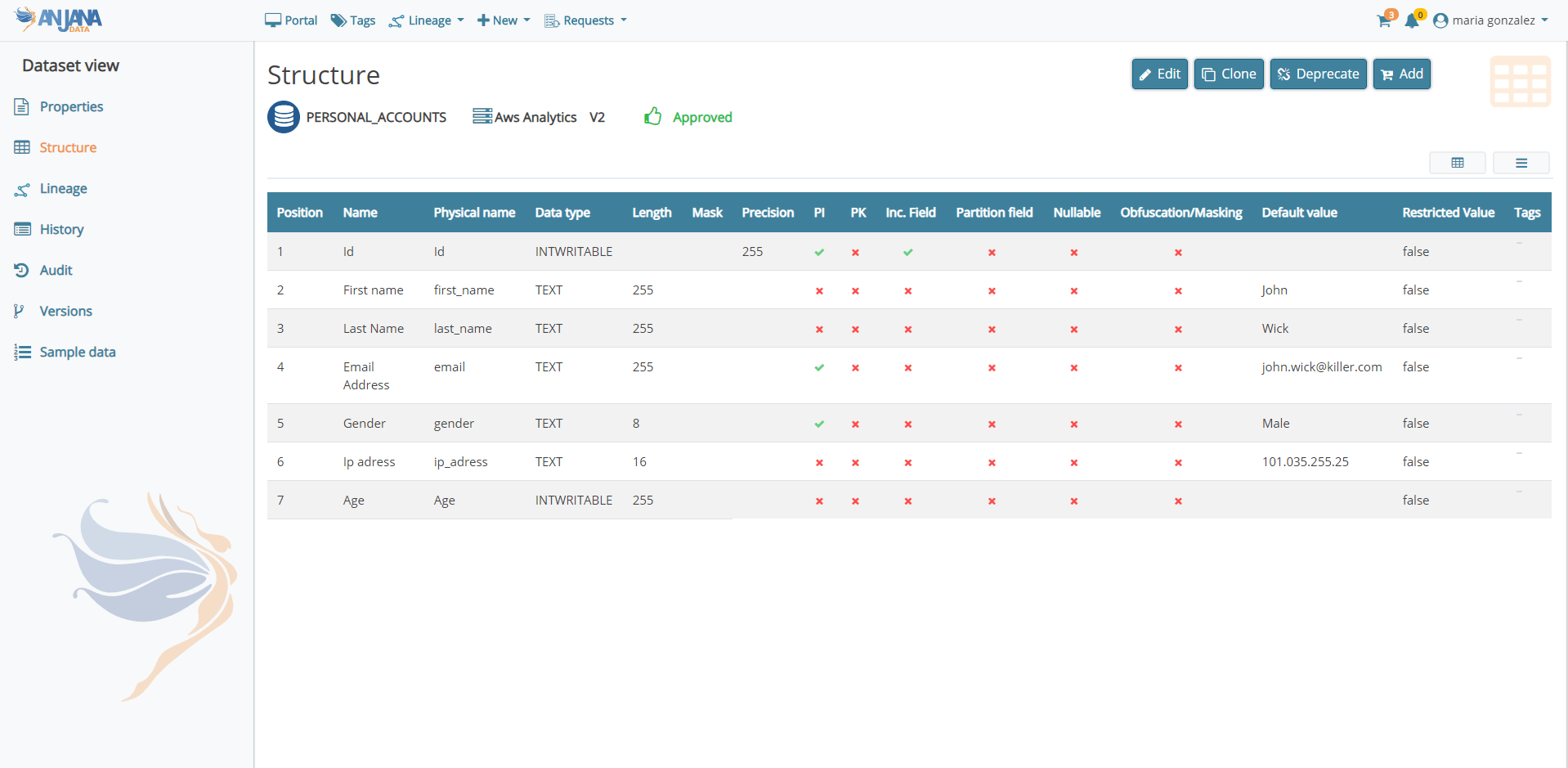
In the new version, Anjana Data’s CORE Metamodel has not only been extended with additional metadata but also now offers the possibility to modify the templates for the different objects. This allows for the centralisation of taxonomy management and the inclusion of new metadata over time, according to the needs of the organisation.
Furthermore, users will be able to add specific metadata to individual objects according to their permission settings and will be able to have predefined data type catalogues for some fields based on supported technologies and formats.
Active government and dynamic lineage agnostic to technology and on new platforms natively
Being the only data governance solution that offers active government and dynamic lineage agnostic to data storage and processing technologies is not easy and, therefore, this new version of Anjana Data brings with it a new simplified architecture, specifically designed to facilitate interaction with any technology through the use of services and offering in-memory computing capabilities with unlimited horizontal scalability (yes, unlimited, Big Data style).
Similarly, to allow full interoperability and ensure quick and easy integration into any technology scenario, Anjana Data has a new optimised public API layer that is fully documented. This layer has been extended with new features to offer all the capabilities of Anjana Data to the outside world, both inbound and outbound.
In addition, work has continued on native integration with different vendors and technologies such as the entire Cloudera stack (CDH and CDP), any stand-alone Hadoop cluster that uses technologies such as Sentry, HDFS, Impala, Hive, Spark 2.x, … and support for all technologies that comply with the JDBC standard (mostly relational databases, both On-Premise and Cloud).
In this way, it has been possible to develop a solution that offers the different roles involved a better working dynamic and optimal management of metadata, facilitating the extraction of value for the business and decision-making.
The future of Anjana Data
This new version offers our customers capability improvements and a significant leap in quality, but, of course, we are already developing the next version, which will be launched in April this year. What can we find in this next version?
- New native integration capabilities with different platforms and technologies, which we will be announcing as we finalise the corresponding partnership agreements that we are managing.
- The new jewel in the crown, a state-of-the-art Business Glossary module, totally flexible and configurable to adapt to the semantic vision of any organisation, but 100% connected to our central metamodel, offering the possibility of a complete data journey both top-down and bottom-up.
- Forms dinámicas avanzadas para gestionar plantillas y composición de objetos
Redesign of some interfaces and inclusion of UX and UI improvements with the aim of making Anjana Data's web application increasingly simple and intuitive and favouring the interaction of different types of roles and users. - And, the icing on the cake, assistance capabilities for some functionalities, thanks to the analysis of user behaviour and the inclusion of advanced analytics algorithms in the background. That which everyone likes to call «Artificial Intelligence» and «Machine Learning».


